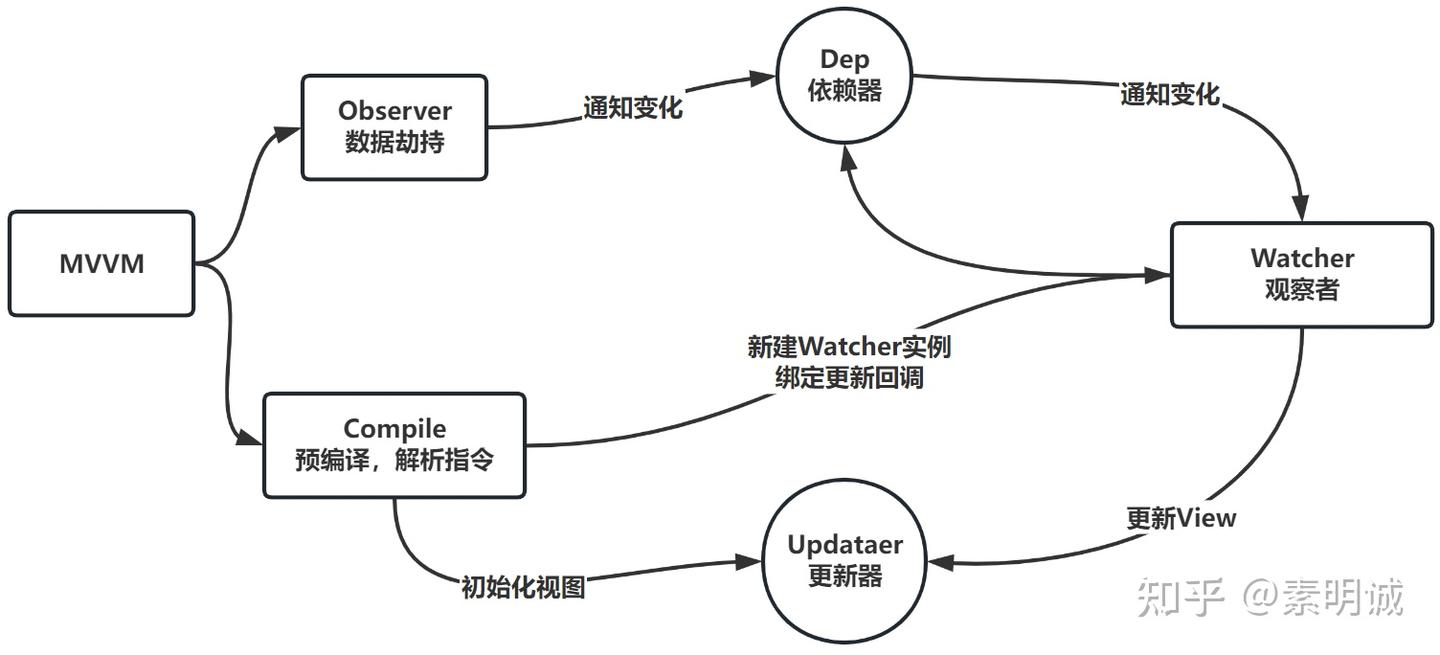
实现 MVVM
· 阅读需 1 分钟
前端开发技术文章
查看所有标签^1[345678]\d{9}$
^[1-9][0-9]{4,9}$
#?([0-9a-zA-Z]{6}|[0-9a-zA-Z]{3})
^([0-9a-zA-Z_\.\-]+)@([0-9a-zA-Z_\.\-]+)\.([A-Za-z]{2,6})$
^((https?|ftp|file):\/\/)?([\da-z\.\-]+)\.([a-z\.]{2,6})([\/w\.\-]*)*\/?$
^<([a-z]+)([^>]+)*(?:>(.*)<\/\1>|\s+\/>)$
^((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)$
^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])$
/^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/
^[1-9]\d{5}(18|19|20)\d{2}((0[1-9])|(1[0-2]))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$
CDN:常用的包用CDN 代替,https://www.bootcdn.cn/Expires或者Cache-Control响应头来设置缓存,尽可能的使用本地缓存,减少服务器压力,增强用户体验Gzip压缩:注意!!! 图片和PDF文件不要使用gzip。它们本身已经压缩过,再使用gzip压缩不仅浪费 CPU资源,而且还可能增加文件体积。ETag:Etag通过文件版本标识,方便服务器判断请求的内容是否有更新,如果没有就响应304命中本地缓存,避免重新下载。src的img标签:src属性为空时,浏览器在渲染的过程中仍会将href属性或src属性中的空内容进行加载,直至加载失败,这样就阻塞了页面中其他资源的下载进程,而且最终加载到的内容是无效的,因此要尽量避免。可以使用一个Base64的图片来作为骨架屏。CSS类名的嵌套深度CSS表达式:在前端这块避免使用CSS表达式,因为它的重绘次数非常多,相当的影响性能。但是calc方法不会有性能问题Sass/Scss/Less 要尽可能合并相同的样式规则CSS 压缩工具压缩 CSS 文件<link rel="preload" href="style.css" as="style">
DOM的渲染JavaScript和CSSDOM样式setTimeout、setInterval,使用时候用变量接收移除并赋值为nulldocumentFragment来减少 DOM操作的次数forEach方法取代 for 循环。CPU密集型的场景可以使用Web Workersv-show,减少DOM操作v-for的时候必须添加Key ,没有Key就用nanoIdv-for和v-if连用,当它们处于同一节点,v-for 的优先级比**v-if 更高**,这意味着 v-if 将分别重复运行于每个 v-for 循环中freeze对象export default {
data: () => ({
users: {}
}),
async created() {
const users = await axios.get("/api/users");
this.users = Object.freeze(users);
}
};
image-webpack-loader来压缩图片SourceMap解决构建后的项目无法精准定位错误的问题webpack-bundle-analyzerTree Shaking剔除JS死代码,它正常工作的前提是代码必须采用ES6的模块化语法Chrome Performance:使用Chrome开发者工具分析页面性能ChromeGit管理代码,而不是使用SVNESlint保证编码风格因为Vue是异步更新DOM的,数据改变就会开启异步更新队列,等待队列中所有数据变化完成后再统一更新,这样做可以减少不必要的DOM操作。
Vue 的 $nextTick ,用于在下次 DOM 更新循环结束之后执行延迟回调。它的实现主要是利用了 JavaScript 引擎的微任务机制,通过在当前任务结束后,把回调函数加入到微任务队列,实现了下次 DOM 更新循环结束之后再执行回调函数的效果。
Vue.prototype.$nextTick = function (fn) {
// 将回调函数加入到 Promise 队列
Promise.resolve().then(fn);
};
该代码的实现原理是:在 JavaScript 中,Promise 是一个微任务,当当前任务结束后,它会被添加到微任务队列,并在下一轮微任务中执行。因此,通过在 $nextTick 函数中调用 Promise.resolve().then(fn),可以实现在下一次微任务中执行 fn 回调函数的效果。
let arr = [1, 2, 3, 4, 5, 3, 2];
// 方法1:使用 Set 去重
let set = new Set(arr);
let uniqueArr = Array.from(set);
// 方法2:使用 filter 过滤重复元素
let uniqueArr = arr.filter((item, index) => arr.indexOf(item) === index);
// 方法3:使用 for 循环去重
let uniqueArr = [];
for (let i = 0; i < arr.length; i++) {
if (uniqueArr.indexOf(arr[i]) === -1) {
uniqueArr.push(arr[i]);
}
}
let arr = [3, 1, 5, 4, 2];
// 方法1:使用 sort 排序
arr.sort((a, b) => a - b);
// 方法2:使用 for 循环排序
for (let i = 0; i < arr.length - 1; i++) {
for (let j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
let temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
let str = 'hello world';
// 方法1:使用 split、reverse、join 实现
let reverseStr = str.split('').reverse().join('');
// 方法2:使用 for 循环实现
let reverseStr = '';
for (let i = str.length - 1; i >= 0; i--) {
reverseStr += str[i];
}
let arr = [1, 2, 3, 4, 5, 6, 7, 8, 9];
// 二分查找
function binarySearch(arr, target) {
let low = 0, high = arr.length - 1;
while (low <= high) {
let mid = Math.floor((low + high) / 2);
if (arr[mid] === target) {
return mid;
} else if (arr[mid] < target) {
low = mid + 1;
} else {
high = mid - 1;
}
}
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
let template = `
<ul>
<% for(let i=0; i < data.length; i++) { %>
<li><%= data[i] %></li>
<% } %>
</ul>
`;
let render = (template, data) => {
let evalExpr = /<%=(.+?)%>/g;
let expr = /<%([\s\S]+?)%>/g;
template = template
.replace(evalExpr, (match, code) => `' + ${code} + '`)
.replace(expr, (match, code) => `'; ${code}; html += '`);
let html = `let html = '${template}'; return html;`;
return new Function('data', html)(data);
};
let data = [1, 2, 3, 4, 5];
let html = render(template, data);
console.log(html);
function bubbleSort(arr) {
for (let i = 0; i < arr.length; i++) {
for (let j = 0; j < arr.length - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
let temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
return arr;
}
let arr = [5, 4, 3, 2, 1];
console.log(bubbleSort(arr));
function deepClone(obj) {
let result = Array.isArray(obj) ? [] : {};
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
if (typeof obj[key] === 'object') {
result[key] = deepClone(obj[key]);
} else {
result[key] = obj[key];
}
}
}
return result;
}
let arr = [1, 2, 3, 4, 5];
let max = arr.reduce((a, b) => Math.max(a, b));
let min = arr.reduce((a, b) => Math.min(a, b));
console.log(max, min);
function isPalindrome(str) {
return str === str.split('').reverse().join('');
}
function isPalindrome(str) {
let len = str.length;
for (let i = 0; i < len / 2; i++) {
if (str.charAt(i) !== str.charAt(len - 1 - i)) {
return false;
}
}
return true;
}
function isPalindrome(str) {
return str === str.split(/[\W_]/g).reverse().join('');
}
const bfs = (root, target) => {
const queue = [root];
while (queue.length) {
const node = queue.shift();
if (node.value === target) return node;
node.children.forEach(child => queue.push(child));
}
return null;
};
const dfs = (node, target) => {
if (node.value === target) return node;
for (const child of node.children) {
const result = dfs(child, target);
if (result) return result;
}
return null;
};
动态规划 (Dynamic Programming) 是一种用于解决最优化问题的算法。在背包问题中,我们需要选择物品,以便在不超过背包容量的情况下获得最大价值。
function knapsack(capacity, weights, values, n) {
let i, w;
let K = [];
for (i = 0; i <= n; i++) {
K[i] = [];
}
for (i = 0; i <= n; i++) {
for (w = 0; w <= capacity; w++) {
if (i === 0 || w === 0) {
K[i][w] = 0;
} else if (weights[i - 1] <= w) {
K[i][w] = Math.max(
values[i - 1] + K[i - 1][w - weights[i - 1]],
K[i - 1][w]
);
} else {
K[i][w] = K[i - 1][w];
}
}
}
return K[n][capacity];
}
let values = [3, 4, 5];
let weights = [2, 3, 4];
let capacity = 5;
let n = values.length;
console.log(knapsack(capacity, weights, values, n));
在这段代码中,我们创建了一个二维数组 K,用于记录所有的子问题的解。对于每一个物品,我们考虑是否将其放入背包中,以获得最大价值。最终,我们可以在 K[n][capacity] 中找到最终的答案。
使用input获取文件,生成文件的MD5 ,在上传文件的时候,可以先生成文件的 MD5,把 hash 发给后端方便后端校验。
使用Blob.prototype.slice 或者 File.prototype.slice方法切割文件
async function splitFile(file, chunkSize = 1024 * 1024) {
const fileSize = file.size;
const chunks = Math.ceil(fileSize / chunkSize);
let currentChunk = 0;
while (currentChunk < chunks) {
const start = currentChunk * chunkSize;
const end = start + chunkSize >= fileSize
? fileSize
: start + chunkSize;
const chunk = file.slice(start, end);
const blob = new Blob([chunk], { type: file.type });
// 对每一块进行操作
await uploadChunk(blob, currentChunk, chunks);
currentChunk++;
}
}
async function uploadChunk(chunk, index, total) {
// 上传
}
向服务端发送上传文件的MD5值和分片数量,开始上传
初始化每一个分片上传任务,返回本次分片上传唯一标识
上传失败要返回:分片信息、文件名称、文件hash、分片大小、分片序号等,可以使用Promise.allSettled()
上传成功:服务端合并文件,校验文件hash,得到原始文件,返回成功信息
断点续传其实就是让请求可中断,然后在接着上次中断的位置继续发送,此时要保存每个请求的实例对象,以便后期取消对应请求,并将取消的请求保存或者记录原始分块列表取消位置信息等,以便后期重新发起请求
(new XMLHttpRequest()).abort() 取消请求new CancelToken(function (cancel) {}) 取消请求(new AbortController()).abort() 取消请求你可以每次上传成功后将成功的分片信息保存在本地,刷新后再读取一下,再继续传
Promise.race()来同时请求,用Promise.all()来确定都完成了在使用js-md5生成 MD5 的时候,页面可能会假死,可以使用worker线程进行大文件md5加密的优化,防止页面卡死
秒传就是服务器有这个文件,所以你可以在上传前先请求一下服务器,看看hash是否一致,如果有直接返回上传成功。
Worker - Web API 接口参考 | MDN## 有哪些实际用处?
Worker 线程中全局对象为 self,代表子线程自身,这时 this指向self,其上有一些 api:
self.postMessage: worker 线程往主线程发消息,消息可以是任意类型数据,包括二进制数据self.close: worker 线程关闭自己self.onmessage: 指定主线程发 worker 线程消息时的回调,也可以self.addEventListener('message',cb)self.onerror: 指定 worker 线程发生错误时的回调,也可以 self.addEventListener('error',cb)Web Workers把需要大量计算的工作交接给worker处理,不占用主线程。postMessage和onmessage进行信息的传递和接收。主线程与 Worker 之间传递的数据是通过拷贝完成的,而传址来完成的。传递给 Worker 的对象需要经过序列化,接下来在另一端还需要反序列化。页面与 Worker 不会共享同一个实例,最终的结果就是在每次通信结束时生成了数据的一个副本。
也就是说,Worker 与其主页面之间只能单纯的传递数据,不能传递复杂的引用类型:如通过构造函数创建的对象等。并且,传递的数据也是经过拷贝生成的一个副本,在一端对数据进行修改不会影响另一端。
缺点
worker 不支持跨域请求worker不能访问document和window,但是可以获取navigator、location(只读)、XMLHttpRequest、setTimeout等浏览器 API。也可以进行AJAX请求。worker可以委派多个worker// 加载其他的worker
importScripts('...')
terminate()可以终止worker<script>
let Str = 'Nothing is to be got without pains but poverty';
let changeString = 'poverty9 Nothing1 without6 pains7 but8 is2 to3 be4 got5';
// 根据单词末尾的下标,还原句子
// 方法1 sort
let processString1 = changeString.split(' ').sort((a, b) => {
return a.slice(- 1) - b.slice(- 1);
}).join(' ');
console.log(processString1);
// 方法2 map
let processString2 = changeString.split(' ').map((e) => {
return {
index: e.slice(- 1),
value: e.slice(0, e.length - 1)
};
}).sort((a, b) => {
return a.index - b.index;
}).map((e) => {
return e.value;
}).join(' ');
console.log(processString2);
</script>
在 Vue 文档列表渲染中,明确提到一句话

这里提到了除非可以依赖默认行为以获取性能上的提升,除了这种情况以外是一定要使用 key 的。
在 Vue 中更新视图的时候我们需要通过 diff 算法对新旧 DOM 进行比较差异,重新渲染。key 在这里起到的作用就是一个唯一标识,为了更高效的对比虚拟 DOM 中每个节点是否相同。
Vue 采用“就地更新”的策略来更新 DOM,当数据项的顺序发生改变,Vue 不会随之移动 DOM 元素的顺序,而是就地更新每个元素。
为什么要采用这种方式?
因为这种方式是高效的,尤其是在用于列表渲染的时候,Vue 会尽可能复用相同元素。如果使用 index 有时候会导致渲染异常或者错位的现象。
所以,尽可能使用 key 并保障 key 是唯一的,如果没有唯一值可以使用 nanoId 等其他的库来生成 key
 ## 源码
## 源码