Python 去除文件名称内的特殊字符
· 阅读需 1 分钟
import os
import re
def sanitize_filename(filename):
""" 使用'-'替换文件名中的特殊字符和空格 """
return re.sub(r'[^\w.-]', '-', filename)
def rename_files_in_directory(directory):
""" 遍历目录并重命名文件 """
for root, dirs, files in os.walk(directory):
for filename in files:
# 生成新文件名
new_filename = sanitize_filename(filename)
if new_filename != filename:
# 构建完整的文件路径
original_file_path = os.path.join(root, filename)
new_file_path = os.path.join(root, new_filename)
# 重命名文件
os.rename(original_file_path, new_file_path)
print(f"已将文件 {filename} 重命名为 {new_filename}")
def main():
# 获取当前脚本的目录
current_directory = os.path.dirname(os.path.abspath(__file__))
# 开始重命名流程
rename_files_in_directory(current_directory)
print("所有文件处理完毕!")
if __name__ == '__main__':
main()
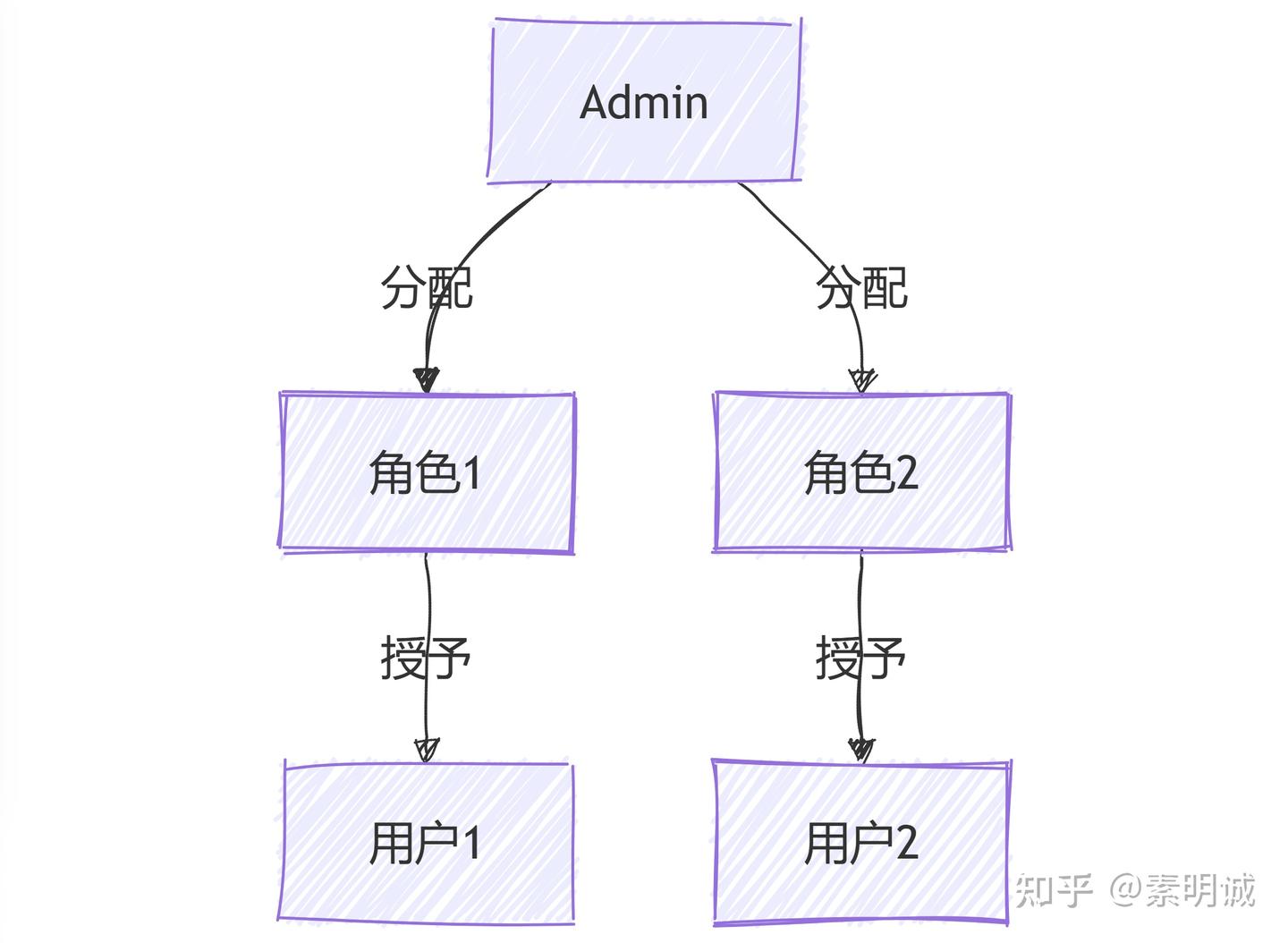 ### RBAC1 - 具有角色层级的 RBAC
### RBAC1 - 具有角色层级的 RBAC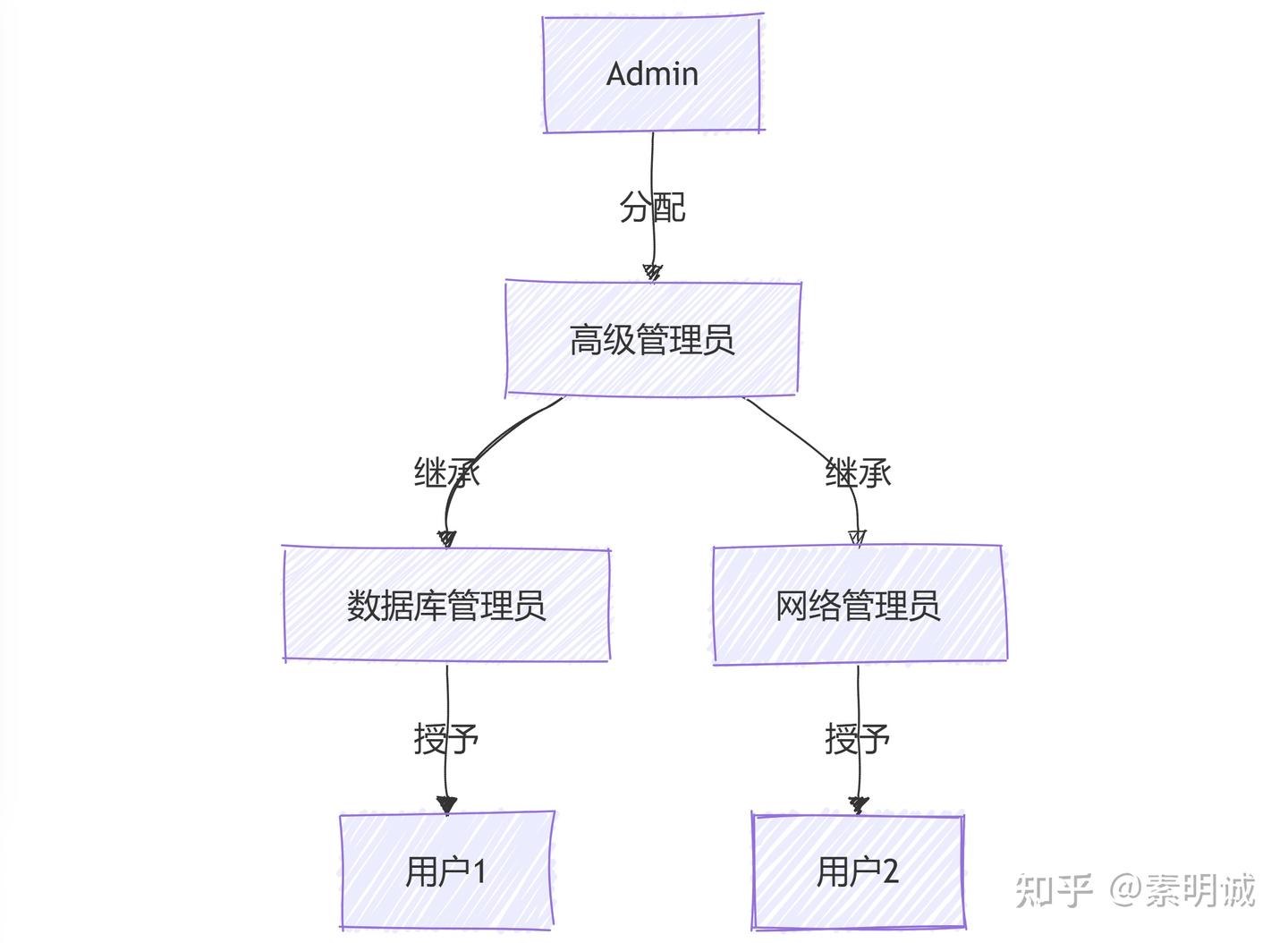 ### RBAC2 - 具有约束的 RBAC
### RBAC2 - 具有约束的 RBAC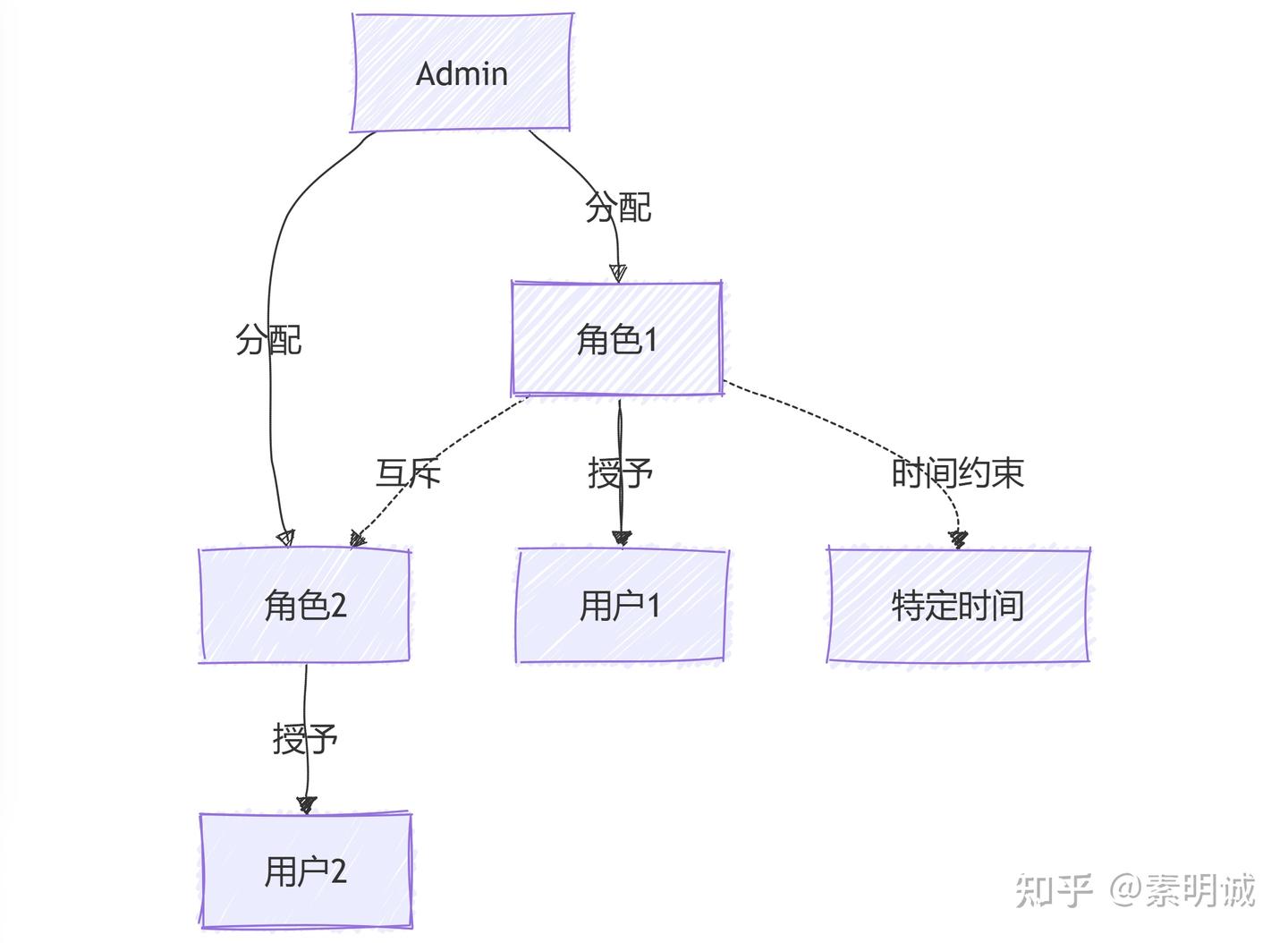 ### RBAC3 - 综合 RBAC
### RBAC3 - 综合 RBAC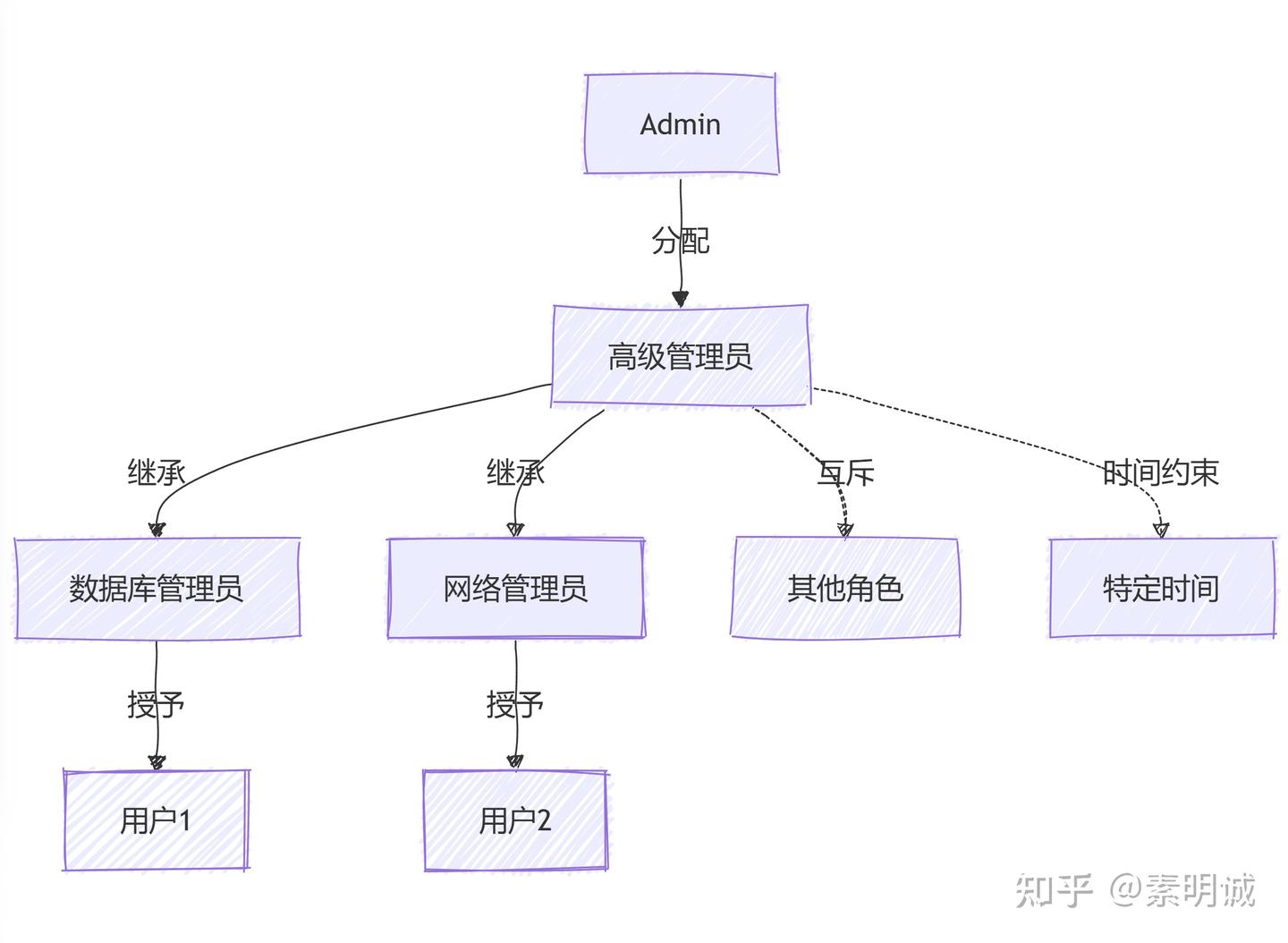
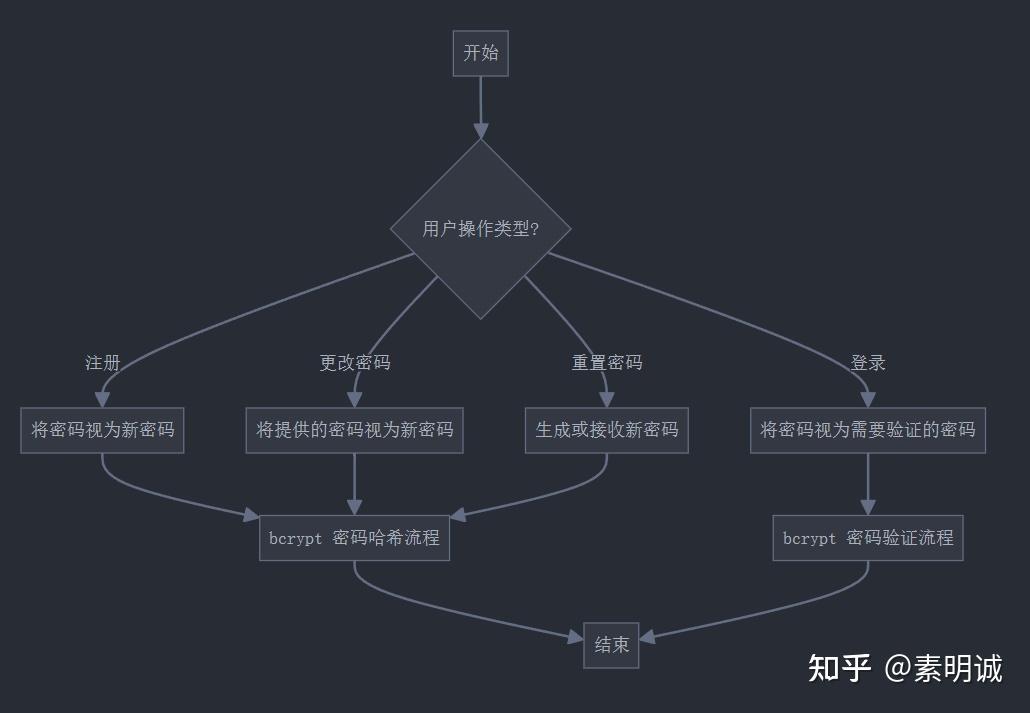 ## 解密原理
## 解密原理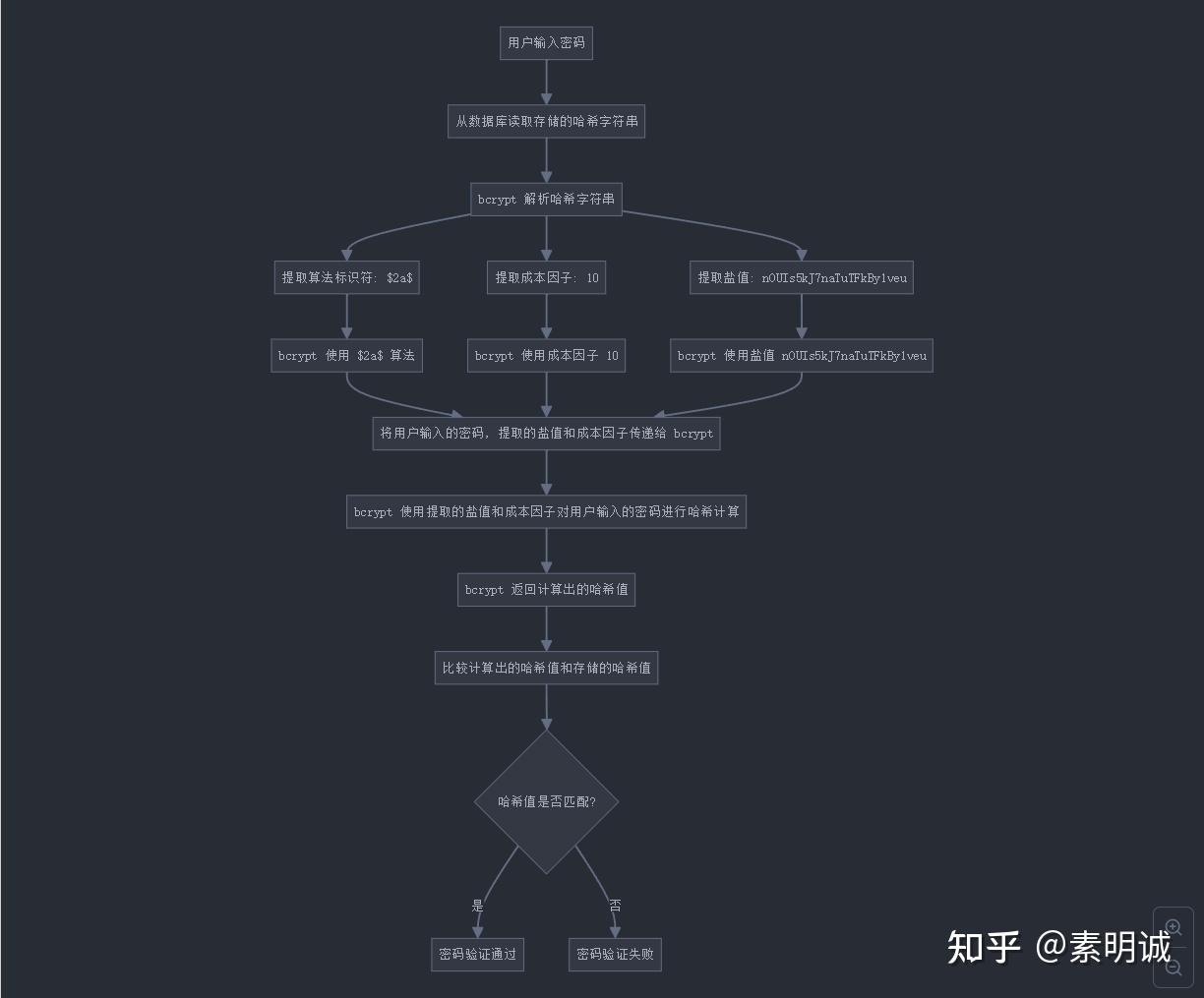 ## Go 加密解密示例代码
## Go 加密解密示例代码