这是一份记录斯坦福大学一场关于人工智能(AI)的讲座的文档,讲者是埃里克·施密特。以下是对这份文档内容的详细翻译:
今天的嘉宾真的不需要介绍。 我想我大约 25 年前第一次见到埃里克是在他作为 Novell 的 CEO 来到斯坦福商学院的时候。 从那以后,他在 Google 做了一些事情,从 2001 年开始,然后从 2017 年开始创建了 Schmidt Futures,并做了很多其他的事情,你可以读到关于他的信息,但他今天只能在这里待到 5 点 15 分,所以我想我们直接深入一些问题,我知道你们也提了一些问题。 我这里写了一堆问题,但我们刚刚在楼上谈论的内容更有趣,所以我只想从那里开始,埃里克,如果可以的话,从短期来看你如何看待 AI 的发展?我认为你定义的是未来一两年。 事情变化如此之快,我感觉每六个月我都需要重新发表一个关于即将发生的事情的演讲。
有人能听到电脑的声音吗,计算机科学工程师,有人能为班上其他同学解释一下什么是百万标记上下文窗口吗? 你在这里。 说出你的名字,告诉我们它是做什么的。 基本上它允许你用大约一百万个标记或一百万个词进行提示。 所以你可以问一个一百万字的问题。
是的,我知道这是一月份一个非常大的方向。 不,不,他们要到 10。 是的,其中几个。 Anthropic 正在从 200,000 发展到一百万等等。 你可以想象 OpenAI 有类似的目标。
这里有人能给出一个 AI 代理的技术定义吗? 是的,先生。 所以代理是做某种任务的东西。 另一个定义是它是内存中的 LLM 状态。 再次,计算机科学家,你们中的任何人可以定义文本到行动吗?
将文本转化为行动? 就在这里。 继续。 是的,不是把文本转换成更多的文本,而是让 AI 触发行动。 所以另一个定义是语言到 Python,一个我从未想过会生存下来的编程语言,而 AI 中的一切都是用 Python 完成的。
有一个叫做 Mojo 的新语言刚刚出现,看起来他们终于解决了 AI 编程的问题,但我们将看到它是否能在 Python 的主导地位下生存下来。 再一个技术问题。 为什么 NVIDIA 值 2 万亿美元,而其他公司则在挣扎? 技术答案。 我认为这主要归结为大多数代码需要运行 CUDA 优化,目前只有 NVIDIA GPU 支持。
其他公司可以做任何他们想做的事情,但除非他们有 10 年的软件,否则你不会有机器学习优化。 我喜欢把 CUDA 想象成 GPU 的 C 编程语言。 这就是我喜欢的方式。 它成立于 2008 年。 我一直认为这是一种糟糕的语言,然而它已经变得主导。
还有一个见解。 有一套开源库,它们高度优化到 CUDA 而不是其他任何东西,每个构建所有这些堆栈的人都完全忽略了这一点。 它在技术上被称为 VLM 和一大堆类似的库。 高度优化的 CUDA,如果你是竞争对手,很难复制。 那么这一切意味着什么?
在未来一年中,你将看到非常大的上下文窗口,代理和文本到行动。 当它们在规模上交付时,它将对世界产生一种尚未被人理解的影响。 在我看来,这比我们通过社交媒体造成的可怕影响要大得多。 所以这就是原因。 在上下文窗口中,你基本上可以将其用作短期记忆,我很震惊上下文窗口能这么长。
技术原因与它难以服务、难以计算等有关。 关于短期记忆的有趣之处在于,当你提问时,你读了 20 本书,你给出这些书的文本作为查询,并且你说,告诉我它们说了什么。 它忘记了中间部分,这也正是人类大脑的工作方式。 这就是我们所处的位置。 关于代理,现在有人在构建基本上是 LLM 代理,他们的做法是他们读一些像化学这样的东西,他们发现化学的原理,然后他们进行测试,然后他们将其加回到他们的理解中。
这是非常强大的。 然后第三件事,正如我提到的,是文本到行动。 所以我会给你举一个例子。 政府正在试图禁止 TikTok。 我们将看到这是否真的会发生。
如果 TikTok 被禁,以下是我建议你们每个人都做的。 对你的 LLM 说以下话。 让我复制一个 TikTok,窃取所有用户,窃取所有音乐,把我的偏好放进去,在接下来的 30 秒内制作这个程序,发布它,如果一小时内没有病毒,就换个类似的方法做点不同的事。 这就是命令。 嘭嘭嘭嘭。
你明白这有多强大吗。 如果你可以从任意语言转换为任意数字命令,这在这种情况下本质上就是 Python,想象一下,地球上的每个人都有自己的程序员,这些程序员实际上是做他们想做的事情,而不是为我工作的程序员,他们不做我要求的事情,对吧? 这里的程序员知道我在说什么。 所以想象一个不傲慢的程序员,实际上做你想让他做的事情,你不需要支付那么多钱,而且这些程序是无限供应的。 这一切都在未来一两年内发生。
很快。 这三件事,我相当确信这三件事的结合将在下一波发生。 所以你问还会发生什么。 每六个月我都会摇摆不定。 所以我们正在进行一场奇数和偶数的摇摆。
所以目前,前沿模型和其他所有人之间的差距在我看来正在变大。 六个月前,我确信差距正在缩小。 所以我在小公司投了很多钱。 现在我不太确定了。 我在和大公司谈,大公司告诉我他们需要 100 亿、200 亿、500 亿、1000 亿。
Stargate 是 1000 亿,对吧? 这非常非常难。 我和 Sam Altman 是亲密的朋友。 他认
为这将需要大约 3000 亿,可能更多。 我指出我已经计算了所需的能量量。
然后在完全披露的精神中,我在周五去了白宫,告诉他们我们需要与加拿大成为最好的朋友,因为加拿大人非常好,帮助发明了 AI,并且有很多水电。 因为作为一个国家,我们没有足够的电力来做这件事。 另一种选择是让阿拉伯人资助它。 我个人很喜欢阿拉伯人。 我在那里度过了很多时间,对吧?
但他们不会遵守我们的国家安全规则。 而加拿大和美国 是三方协议的一部分,我们都同意。 所以这些 1000 亿、3000 亿的数据中心,电力开始成为稀缺资源。 顺便说一句,如果你遵循这种推理,为什么我讨论 CUDA 和 Nvidia?
如果 3000 亿美元都要流向 Nvidia,你知道该在股市中做什么。 好的。 这不是股票推荐。 我没有执照。 好吧,部分原因是我们将需要更多的芯片,但英特尔从美国
政府获得了很多钱,AMD,他们正在试图在韩国建设 fabs。 如果你的计算设备中有英特尔芯片,请举手。 好吧。 所以独占权已经不复存在了。 好吧,这就是问题所在。
他们曾经确实有过独占权。 绝对如此。 而 Nvidia 现在拥有独占权。 那么,像 CUDA 这样的进入壁垒,其他公司有没有什么可以,所以我前几天和 Percy,Percy Landy 谈话,他在 TPUs 和 Nvidia 芯片之间来回切换,取决于他能获得什么来训练模型。 那是因为他别无选择。
如果他有无限的钱,他今天会选择 Nvidia 的 B200 架构,因为它会更快。 我不是在建议,我的意思是,有竞争是好事。 我和 AMD 的 Lisa Sue 谈了很长时间。 他们建造了一个东西,可以将你描述的这种 CUDA 架构转换为他们自己的,叫做 Rockum。 它还不太管用。
他们正在努力。 你在 Google 工作了很长时间,他们发明了变压器架构。 彼得,彼得。 这都是彼得的错。 多亏了那里的一些聪明人,比如彼得和 Jeff Dean 等人。
但现在看起来,他们似乎失去了倡议权,甚至在我看到的最后一个排行榜上,Anthropix 的 Claude 排在首位。 我问过 Sundar 这个问题,他没有给我一个非常明确的答案。 也许,也许你有一个更清晰或更客观的解释这里发生了什么。 我不再是谷歌员工,在完全披露的精神中说。
谷歌决定工作生活平衡和早点回家以及在家工作比赢得更重要。 而初创公司之所以有效,是因为人们努力工作如地狱。 我很抱歉如此直率,但事实是,如果你们都离开大学去创办一家公司,你们不会让人们在家工作,只来上班一天。 如果你想与其他初创公司竞争,像谷歌、微软早期那样。 确实如此。
但现在似乎,在我所在的行业,我们的行业,我想,有一段悠久的历史,公司以一种真正创造性的方式赢得比赛,并真正主宰一个领域,而没有实现下一个转变。 所以我们的记录非常完善。 我认为真相是创始人是特殊的。 创始人需要负责。
创始人很难相处。
他们会对人施加压力。 尽管我们可能不喜欢 Elon 的个人行为,但看看他从人们那里得到了什么。 我和他共进晚餐,他当时在飞行。 我在蒙大拿。 他那天晚上 10 点要飞去与 x.ai 开午夜会议。
我在台湾,不同的国家,不同的文化。 他们说这是台积电,我对此印象非常深刻。 他们有一个规定,即刚从好的物理专业毕业的博士生在工厂的地下室工作。 现在,你能想象让美国的物理学家这么做吗? 博士生,不太可能。
不同的工作道德。 这里的问题是,我对工作如此严厉的原因是,这些是具有网络效应的系统。 所以时间非常重要。 而在大多数业务中,时间并不那么重要。 你有很多时间。
可口可乐和百事可乐仍将存在,可口可乐与百事可乐之间的争斗将继续进行,这一切都是冰川时代的。 当我处理电信公司时,典型的电信公司交易需要 18 个月才能签署。 没有理由花 18 个月来做任何事情。 把它做完。 我们正处于最大增长、最大收益的时期。
而且还需要疯狂的想法。 像微软做 OpenAI 交易时,我认为那是我听过的最愚蠢的想法。 从本质上讲,将你的 AI 领导权外包给 OpenAI 和 Sam 及其团队。 我的意思是,那太疯狂了。 在微软或其他任何地方都不会有人这么做。
然而今天,他们正走在成为最有价值公司的路上。 他们当然与苹果并驾齐驱。 苹果没有一个好的 AI 解决方案,看起来他们让它发挥了作用。 是的,先生。 在国家安全或地缘政治利益方面,你认为 AI 将如何发挥作用,或者与中国的竞争将如何发挥作用?
所以我是一个 AI 委员会的主席,这个委员会非常仔细地研究了这个问题,你可以阅读它。 它大约有 752 页,我只是简单地说我们领先,我们需要保持领先,我们需要大量资金来做到这一点。 我们的客户是参议院和众议院。 由此产生了芯片法案和许多其他类似的东西。 粗略的情景是,如果你假设前沿模型推动前进,以及一些开源模型,很可能只有少数公司可以参与这场游戏。
国家,对不起。 是哪些国家或他们是谁? 拥有大量资金和大量人才,拥有强大的教育系统,并愿意赢得胜利的国家。 美
国是其中之一。 中国是另一个。
还有多少其他国家? 还有其他国家吗? 我不知道。 也许。 但肯定在你们的一生中,美国和中国争夺知识霸权将是一场大战。
所以美国政府基本上禁止了 NVIDIA 芯片,尽管他们不允许说这是他们在做的事情,但他们确实这样做了进入中国。 他们大约有 10 年的芯片优势。 我们大约有 10 年的芯片优势,是在亚 5 丹米以下的芯片方面。 所以今天我们比中国领先几年。 我的猜测是我们将比中国领先几年,而中国人对此非常生气。
这是非常重要的事情。 这是特朗普政府做出的决定,由拜登政府推动。 你认为今天的政府和国会在听你的建议吗? 你认为它将进行那种规模的投资吗?
显然是芯片法案,但除此之外,还建设一个庞大的 AI 系统? 所以你知道,我领导一个非正式的、临时的、非法律的小组。 这与非法的不同。 就是这样。
其中包括所有通常的嫌疑人。 去年,通常的嫌疑人提出了成为拜登政府 AI 法案的基础,这是历史上最长的总统指令的理由。 你在谈论特殊的竞争研究项目吗? 不,这是行政办公室的实际法案。 他们正忙于实施细节。
到目前为止,他们做得很好。 例如,我们在过去一年中进行的辩论之一是,如何在系统中检测到危险,系统已经学会了,但你不知道该问什么? 换句话说,这是一个核心问题。 它学到了一些坏东西,但它不能告诉你它学到了什么,你也不知道该问什么。 还有很多威胁。
就像它以一种新的方式学会了混合化学物质,你不知道该怎么问。 所以人们正在努力解决这个问题。 但我们最终在给他们的备忘录中写道,有一个我们任意命名为 10^26 flops 的阈值,这在技术上是一个计算的度量,超过这个阈值你必须向政府报告你正在做这件事。 这是规则的一部分。 欧盟为了确保他们与众不同,做了 10^25。
但这都差不多。 我认为所有这些区别都会消失,因为技术现在,技术术语被称为联邦训练,基本上你可以将碎片联合在一起。 所以我们可能无法保护人们免受这些新事物的伤害。 好吧,谣言说这就是 OpenEye 不得不接受培训的部分原因,部分原因是电力消耗。 他们没有在一个地方这样做。
好吧,让我们谈谈正在进行的真正战争。 我知道你在乌克兰战争中非常参与,特别是我不知道你能不能谈论白鹳和你的目标,让 50 万美元的无人机摧毁 500 万美元的坦克。 这是如何改变战争的? 我为国防部工作了七年,试图改变我们运行军队的方式。 我不是特别喜欢军队,但这非常昂贵,我想看看我是否能有所帮助。
在我看来,我基本上失败了。 他们给了我一枚勋章,所以他们一定是把勋章给了失败者或其他什么人。 但我自己的批评是没有真正的变化,美国的系统不会导致真正的创新。 所以看着俄罗斯人用坦克摧毁有老太太和孩子的公寓楼,让我疯了。 所以我决定与你的朋友塞巴斯蒂安·特伦一起工作,他是这里的前教职员工,还有一群斯坦福人。
这个想法基本上是做两件事。 使用 AI 以复杂、强大的方式用于这些基本上是机器人的战争,第二个是降低机器人的成本。 现在你坐在那里,你会问,为什么像我这样的好自由主义者会这么做? 答案是,所有军队的整个理论是坦克、火炮和迫击炮,我们可以消除它们,我们可以使入侵一个国家至少通过陆地基本上变得不可能。 它应该消除那种类型的陆地战斗。
嗯,这是一个关系问题,那是不是给了防守方比进攻方更多的优势? 你甚至可以做出这种区别吗? 因为我过去一年一直在做这件事,我学到了很多我真的不想知道的关于战争的事情。 而且要知道的一件事是,进攻总是有优势,因为你总是可以压倒防御系统。 所以你作为国家防御的战略,最好拥有一个你可以在需要时使用的非常强大的进攻。
而我和其他人正在建造的系统将做到这一点。 因为系统的工作方式,我现在是一个持牌武器商,计算机科学家、商人和武器商。 这是一个进步吗? 我不知道。 我不建议你们这样做。
我坚持使用 AI。 由于法律的工作方式,我们是私下进行这些操作的,并且这些都是合法的,得到了政府的支持。 它直接进入乌克兰,然后他们打仗。 在不涉及所有细节的情况下,事情非常糟糕。 我认为如果在 5 月或 6 月,如果俄罗斯像他们预期的那样建立起来,乌克兰将失去一大块领土,并开始失去整个国家的过程。
所以情况非常严峻。 如果有人认识 Marjorie Taylor Greene,我鼓励你把她从你的联系人名单中删除,因为她是一个单独的个体,阻止了向一个重要的民主国家提供几十亿美元的提议。 我想换一个哲学问题。 所以去年你和亨利·基辛格以及 Dan Huttenlecker 一起写了一篇关于知识本质及其演变方式的文章。 昨晚我也讨论了这个问题。
在大多数历史中,人类对宇宙有一种神秘的理解,然后有了科学革命和启蒙运动。 在你的文章中,你们认为现在这些模型变得如此复杂和
非人类,以至于我们基本上回到了信仰的时代。 我们不再理解它们是如何工作的。 你能解释一下吗?
在我看来,这非常简单。 我们建立了一些非常复杂的系统,我参与了其中的一些系统的建立。 我们有些人在这个房间里也是如此。 这些系统可以比人类做得更好。
所以问题是,如果你有一个系统,你问它一个问题,它给你一个答案,这个答案比你得到的任何其他答案都好,你怎么能不信任它? 从技术上讲,这是一种信仰的形式。 我们已经从一个世界转变为另一个世界,而这个新世界是由我们构建的,我们自己的工具和人工智能技术塑造的。 这很奇怪,因为一开始我们说,我们将用这些工具来帮助我们建立一个更好的社会。
但现在看来,这些工具实际上是在重塑我们的社会。 我们是否应该担心它们? 我个人认为,我们应该对此感到非常高兴,因为这些系统将帮助我们解决我们不能解决的问题。 但它们也会带来风险,我们需要管理这些风险。
风险是我们之前讨论过的。 AI 可能会学习错误的事情。 AI 可能会学习如何对人类进行优化,这可能会带来非常严重的后果。 我认为我们应该认真对待这个问题。
所以我们需要监督。 我们需要合适的监管。 我们需要确保 AI 不会做我们不希望它做的事情。 但这是一个非常困难的技术问题,因为 AI 的工作方式非常不同。
它们不像程序或算法那样运行。 它们更像是一种模式或一种可以适应的流程。 我们需要新的工具和方法来理解和控制这些系统。 但这并不意味着我们应该害怕它们。
相反,我们应该拥抱它们,因为它们有巨大的潜力来改善我们的世界。 我们需要小心地使用它们,确保它们为我们服务,而不是反过来。 这就是为什么我认为 AI 的监管如此重要。 我们需要确保它们在帮助我们的同时,不会伤害我们。
那么,当 AI 系统开始展示出非人类的智能形式时,我们应该怎么做? 这是一个很大的问题。 我们需要找到一种方法来理解它们是如何工作的,即使它们的运作方式与我们的完全不同。 这将是 AI 研究的一个重要领域。
但这也是一个非常有趣的时期。 因为 AI 正在向我们展示,智能可以以不同的形式存在。 它不必像人类的智能那样运作。 这给了我们一个机会,去探索智能的新形式,并了解它可以做什么。
这是一个非常激动人心的时期。 但这也是一个需要谨慎的时期,因为我们正在开辟新的领域。 我们不知道这将带我们到哪里。 但这是一个探索的旅程,我认为这将是非常值得的。
现在让我们回到人工智能的安全问题。 如何确保这些非常强大的系统不会对人类造成伤害? 这是我们必须非常严肃对待的问题。 我们需要确保这些系统在进行决策时考虑到人类的福祉。
我们需要建立系统,确保 AI 的决策与我们的价值观和伦理标准一致。 这不会容易。 但这是必须做的,如果我们想利用这些强大的技术改善我们的世界。
如何做到这一点? 我们需要更多的研究。 我们需要更好的技术。 我们需要更智能的 AI。
但我们也需要谨慎。 我们不能让这些系统无限制地运行。 我们需要设立边界,确保它们不会超出我们的控制。 这是一个我们必须非常严肃对待的挑战。
但我相信我们可以做到。 我们有智慧和资源来确保 AI 为我们服务,而不是相反。 这将是一个长期的努力。 但这是一个值得努力的挑战,因为 AI 有可能极大地改善我们的世界。
结束语 我们今天讨论了很多关于人工智能的重要问题。 我希望这些讨论能帮助你们更好地理解这些复杂的技术,以及它们如何影响我们的世界。 感谢大家今天的参与。
原文地址:https://github.com/ociubotaru/transcripts
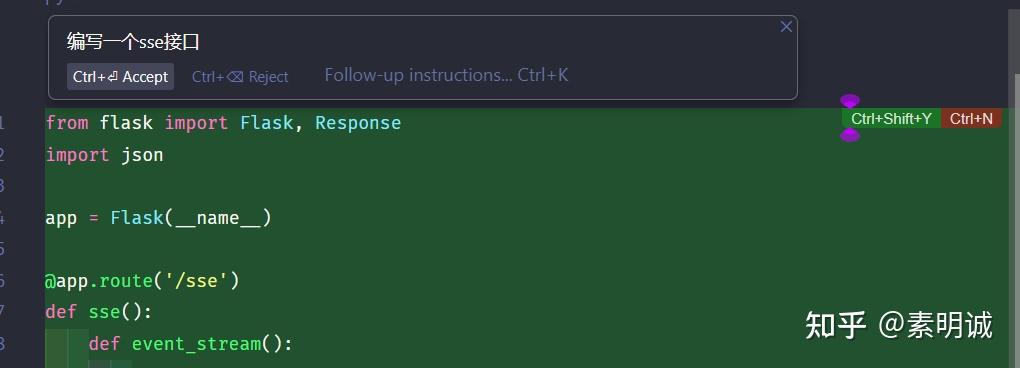
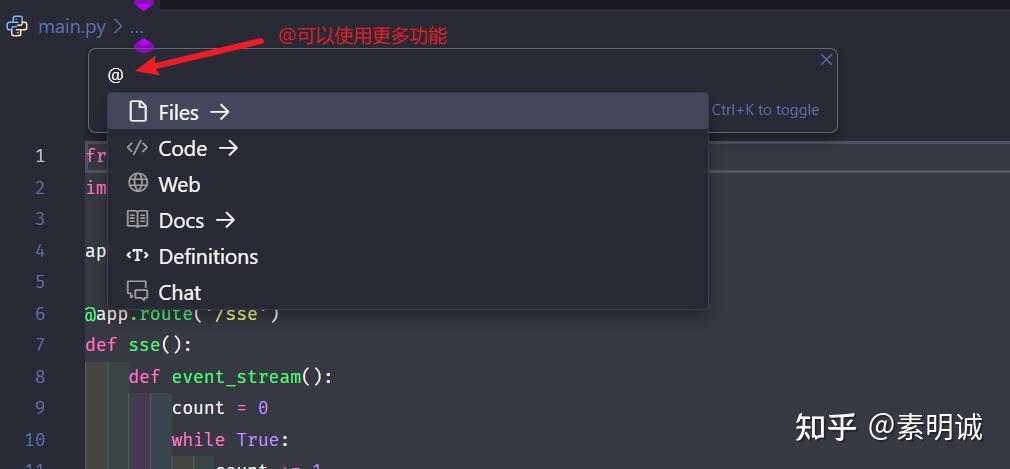
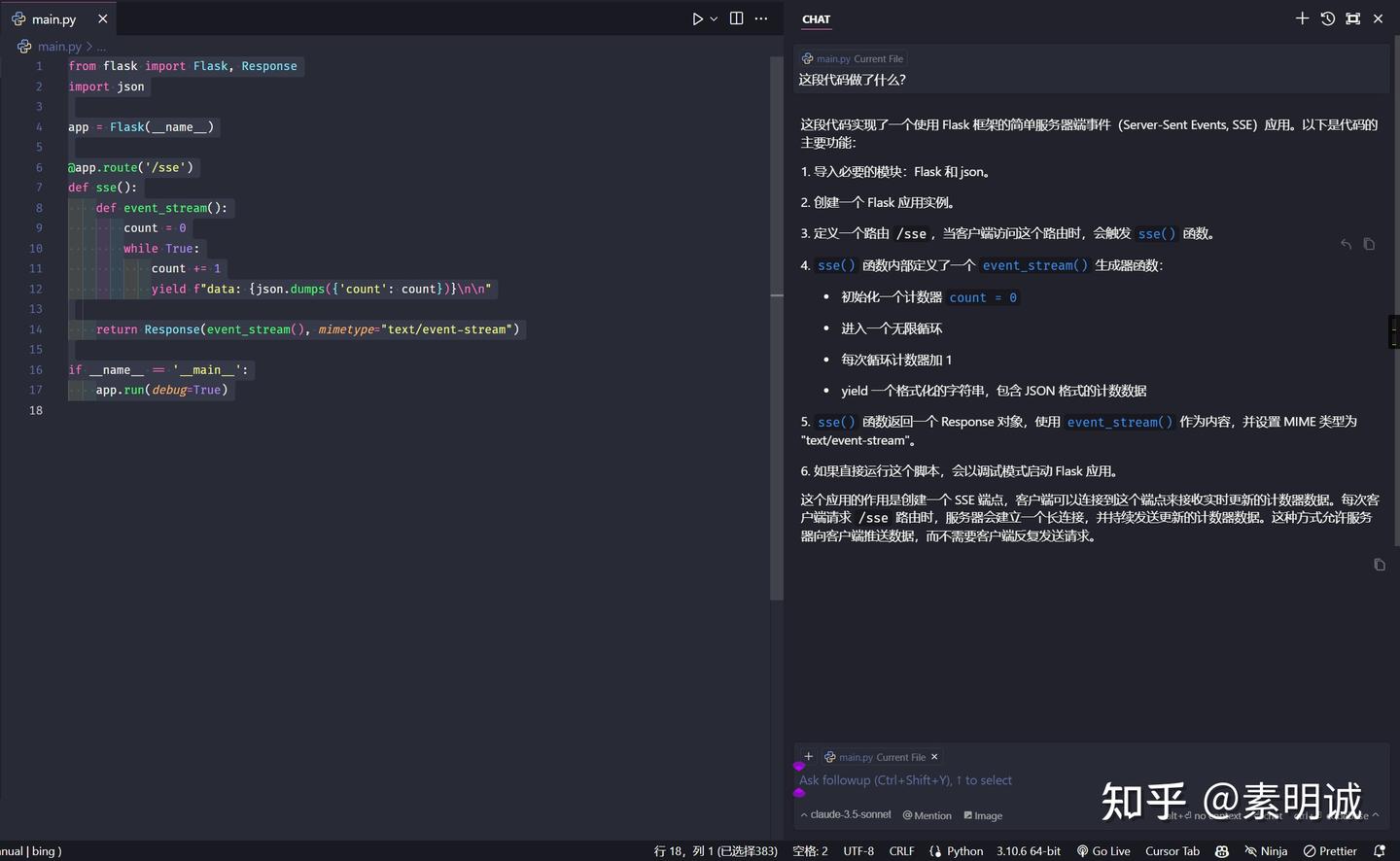 ## 注意事项
## 注意事项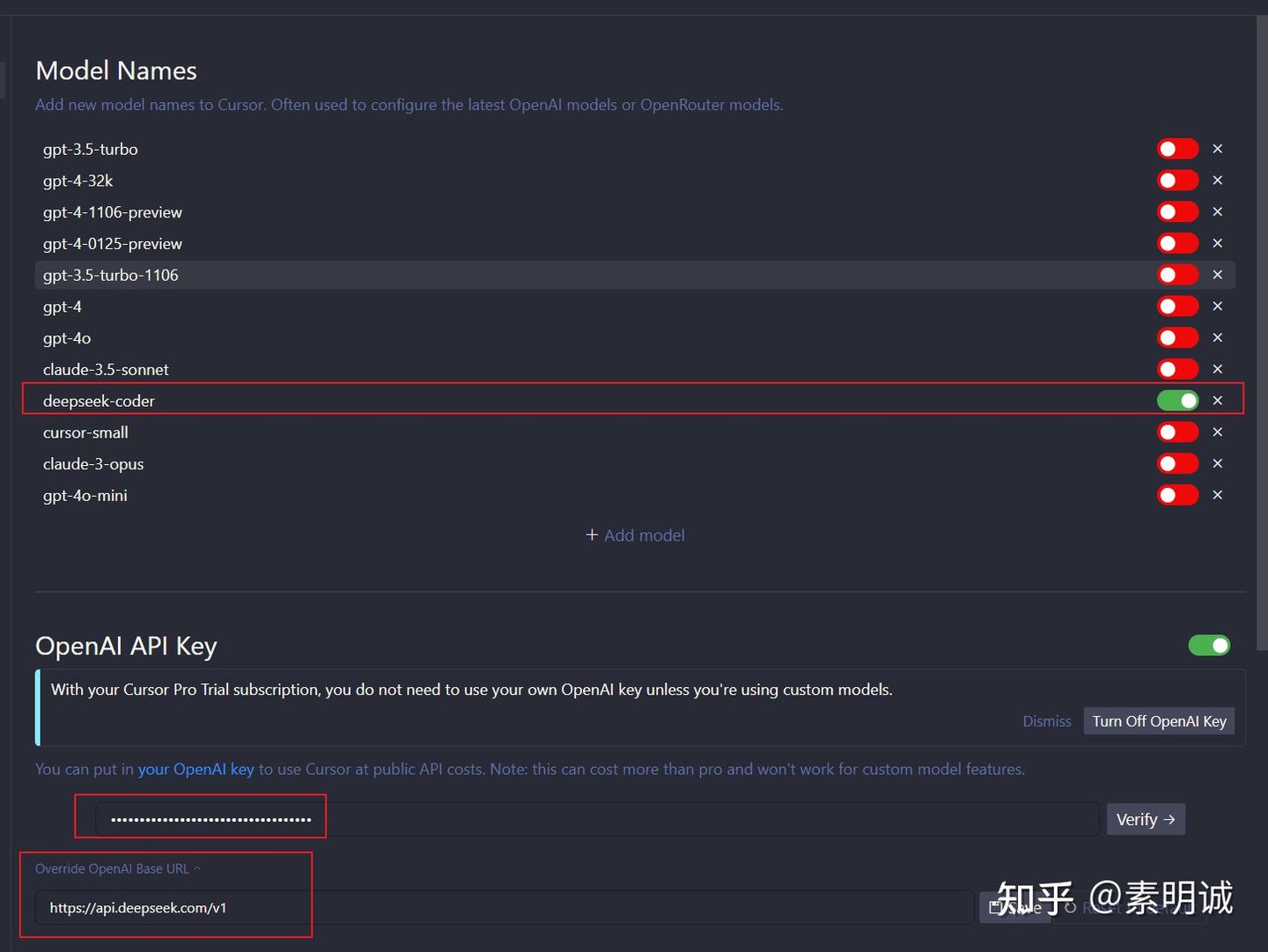
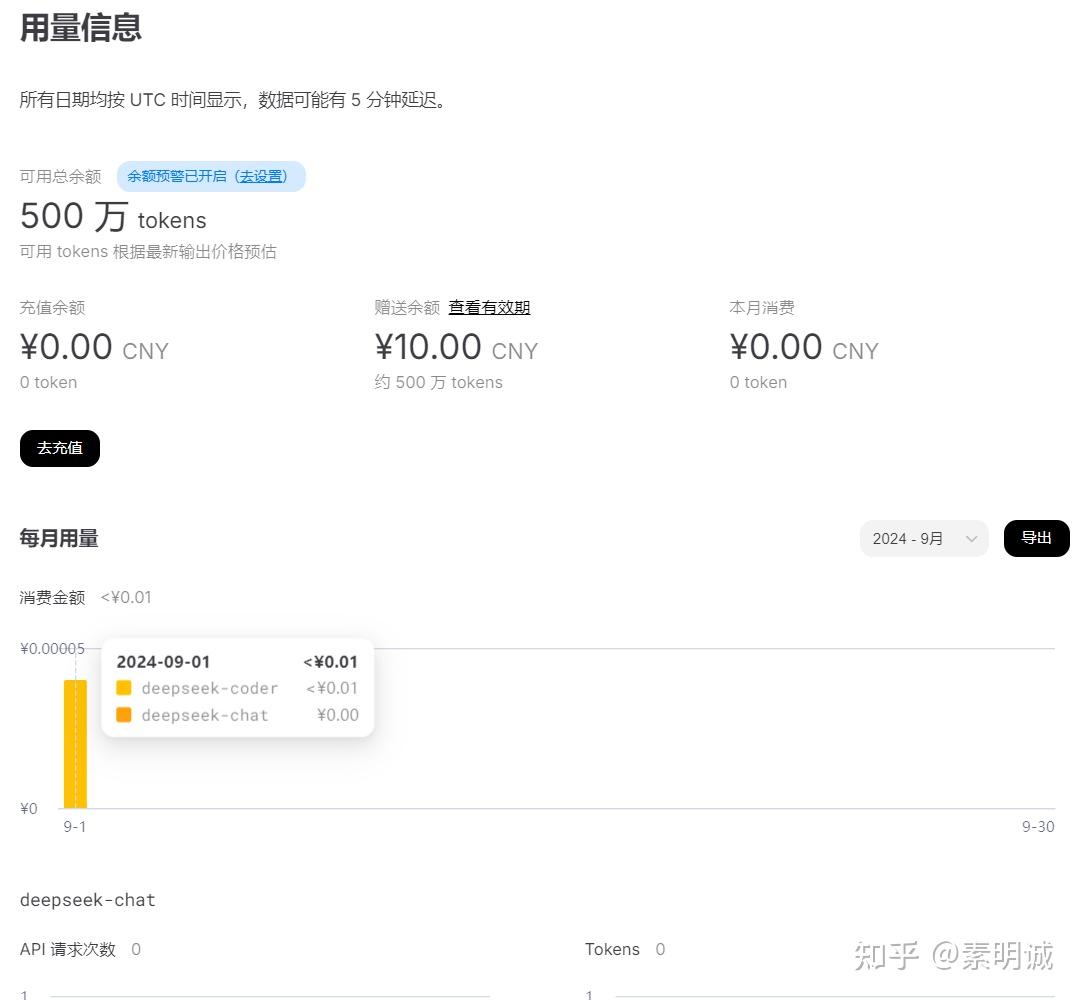
 ### Cursor 配置提示词
### Cursor 配置提示词