递归 和 Memorization
· 阅读需 2 分钟
为什么要在递归中使用记忆化:
- 避免重复计算:许多递归问题的子问题是重复的,这意味着在递归过程中会多次计算相同的子问题。通过存储这些子问题的结果并在需要时检索它们,可以避免这种重复计算,从而节省时间。
- 减少递归深度:对于某些问题,使用记忆化可以减少递归调用的数量和深度,从而避免栈溢出。
- 转换为动态规划:记忆化是将递归算法转换为动态规划算法的一个常见步骤。动态规划是一种特殊的递归,其中每个子问题只解决一次,并将其结果存储在一个表格中,以便后续使用。
下面是一个简单的例子:斐波那契数列。原始的递归解决方案会有很多重复的计算,但使用记忆化可以避免这些重复。
1. 不使用记忆化的递归方法:
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
这个方法的问题是,对于较大的 n,它会进行大量的重复计算。
2. 使用记忆化的递归方法:
为了实现记忆化,我们需要一个数据结构(通常是一个数组或对象)来存储已经计算过的子问题的解。
function fibonacciWithMemo(n, memo = {}) {
// 如果已经计算过这个值,直接从 memo 中返回
if (n in memo) return memo[n];
// 基础情况
if (n <= 1) return n;
// 递归计算并将结果存储到 memo 中
memo[n] = fibonacciWithMemo(n - 1, memo) + fibonacciWithMemo(n - 2, memo);
return memo[n];
}
在这个版本中,使用一个名为 memo 的对象来存储已经计算过的斐波那契数。当函数再次被调用时,它首先检查 memo 对象中是否已经有了该数的值。如果有,则直接返回这个值,从而避免了不必要的重复计算。
 ## min.js 内容
## min.js 内容
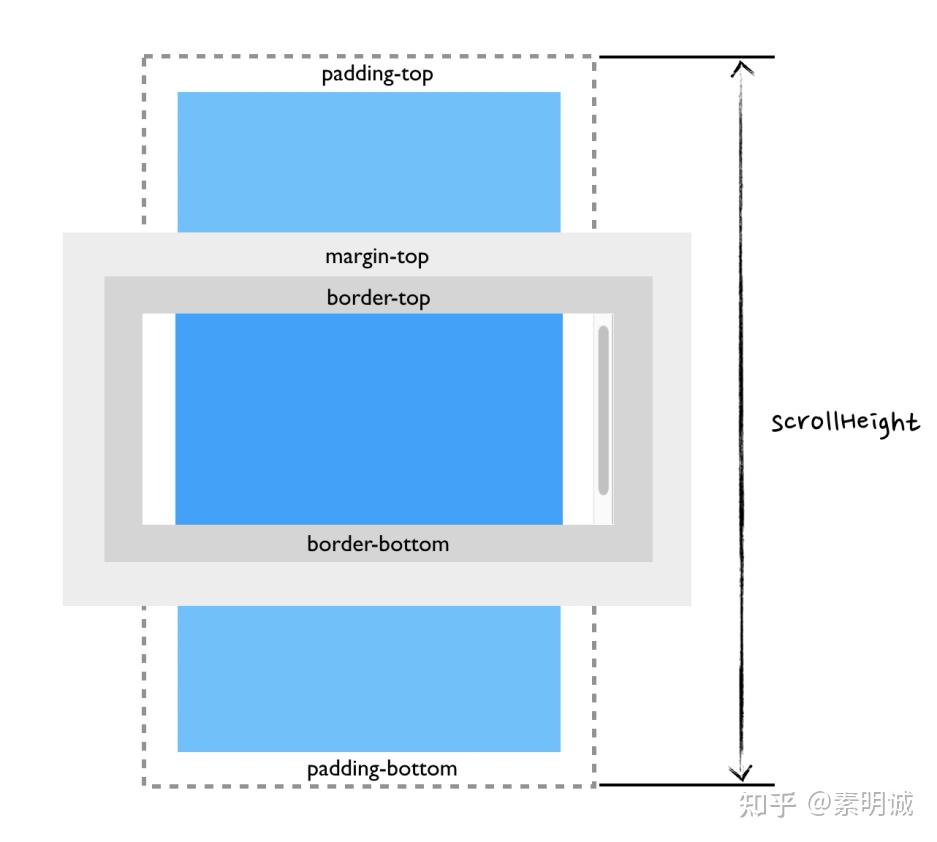 ## scrollTop
## scrollTop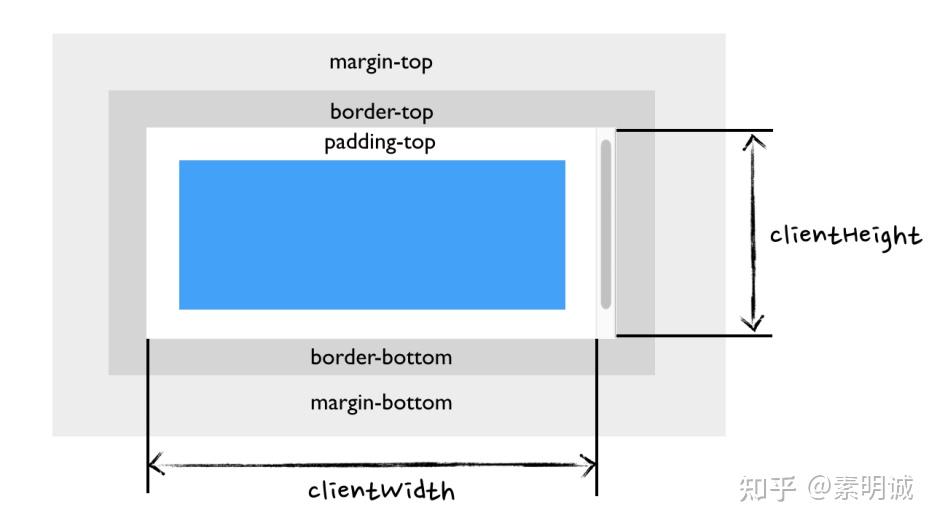 ## 公式
## 公式 ## 方法 1
## 方法 1