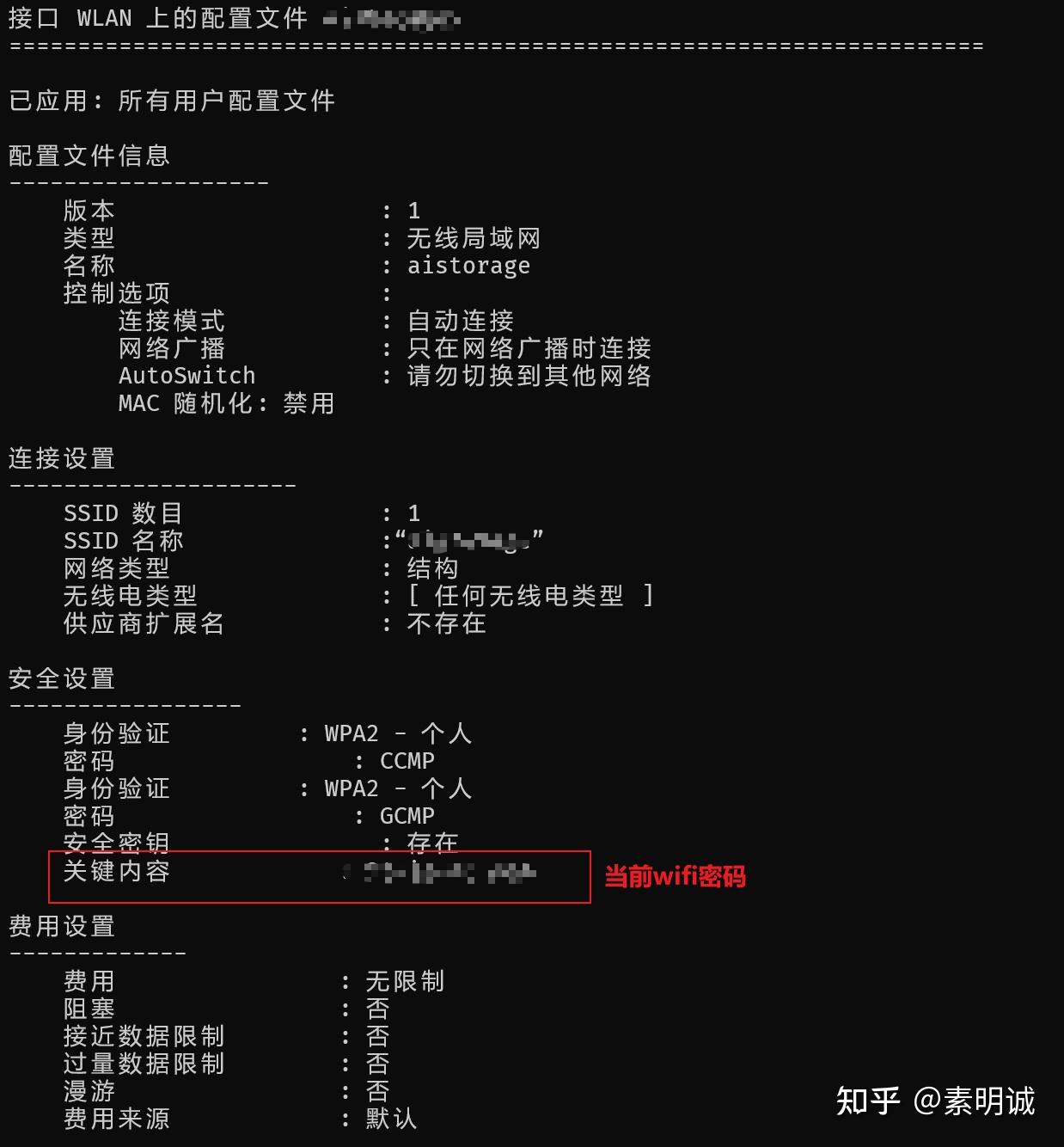
数值数据
原始数据:人的身高 175cm,体重 70kg。
向量化后:175,70175,70。
这里直接使用数值作为向量的元素。
类别数据
原始数据:颜色,选项有“红、黄、蓝”。
向量化后:1,0,01,0,0。
向量化后:0,1,00,1,0。
这种方法称为独热编码,每个位置代表一种颜色,该位置为 1 则表示该颜色,其他位置为 0。
文本数据
原始数据:"The cat sat on the mat."
- 词袋模型(Bag of Words):
向量化后:假设字典中的词有 "the", "cat", "sat", "on", "mat", "dog",则向量可能为 2,1,1,1,1,02,1,1,1,1,0,表示字典中每个词在文本中出现的次数。
- TF-IDF:
向量化后:每个元素是一个词的 TF-IDF 得分,例如 0.3,0.2,0.2,0.2,0.2,00.3,0.2,0.2,0.2,0.2,0,数值表示词的重要性。
图像数据
原始数据:一个 8x8 像素的黑白图像。
向量化后:每个像素值在 0 到 255 之间,将图像展平为一个 64 维的向量 0,255,122,...,430,255,122,...,43。
时间序列数据
原始数据:一周的股票价格 100,102,104,103,105,107,108100,102,104,103,105,107,108。
向量化后:直接使用这个序列作为向量 100,102,104,103,105,107,108100,102,104,103,105,107,108,或者提取特征如平均价格、最大增长率等。
声音和视频数据的向量化稍微复杂一些,因为它们是时间序列数据的多维表示,通常包含大量的信息。下面是声音和视频数据向量化的一些方法和例子。
声音数据
声音数据通常以波形的形式出现,可以通过多种方法向量化,用于后续的处理和分析。
原始数据:一段音频记录。
- 时域分析:直接使用音频的原始波形数据。例如,一段音频文件的振幅值可以直接构成一个向量。
向量化后:0.01,−0.02,0.03,...,−0.010.01,−0.02,0.03,...,−0.01,这些数值代表音频波形在不同时间点的振幅。
- 频域分析(傅立叶变换):将音频信号从时域转换到频域,表示为不同频率成分的强度。
向量化后:5,20,0,3,...,85,20,0,3,...,8,这里每个数值代表了音频中对应频率成分的强度。
- MFCC(梅尔频率倒谱系数):一种在语音识别中常用的特征,它描述了音频信号的短时功率谱在梅尔尺度上的对数。
向量化后:13,−3,2,5,...,713,−3,2,5,...,7,一组 MFCC 系数可以作为音频的特征向量。
视频数据
视频是一系列连续图像帧的集合,通常还伴有音频轨。因此,视频数据的向量化需要考虑空间信息(图像帧)和时间信息(帧序列)。
原始数据:一段视频。
- 帧提取:将视频分解为一系列图像帧,每一帧可以像处理静态图像那样被向量化。例如,可以使用前面提到的图像数据向量化方法。
向量化后:图像帧 1 的向量,图像帧 2 的向量,...图像帧 1 的向量,图像帧 2 的向量,...,视频变成了一系列图像帧向量的集合。
- 时间特征提取:除了提取每一帧的空间特征外,还可以提取表示视频时间演变特征的向量,如通过对连续帧的变化进行编码。
- 深度学习方法:可以使用卷积神经网络(CNN)来处理单个图像帧,以及使用循环神经网络(RNN)或 3D 卷积网络来处理帧序列中的时间关系。
向量化后:利用神经网络,视频可以被编码成一个高维的特征向量,用于视频分类、情感分析等任务。
复杂结构数据
原始数据:一个社交网络图。
向量化后(图嵌入):假设每个用户是图中的一个节点,使用图嵌入技术可能会得到每个用户的向量表示,如用户 A 的向量可能是 0.5,−0.1,0.30.5,−0.1,0.3,这个向量捕捉了用户在社交网络中的位置和连接模式
为什么说所有数据都可以向量化?
向量化的本质是提取数据的特征并用数值来表示这些特征。不同类型的数据,如文本、图像、声音等,虽然它们的特征提取方法和向量化技术各不相同,但最终都能归结为数值表示的形式。