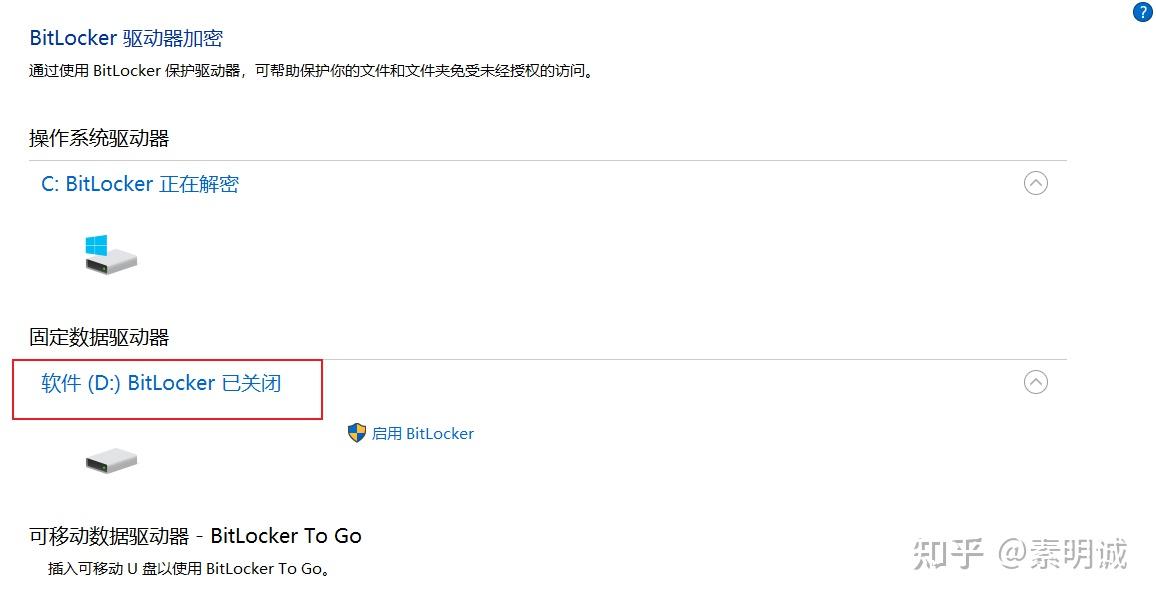
Win10 取消 BitLocker 加密
· 阅读需 1 分钟
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash
wget -qO- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash
安装脚本会将 nvm 安装到你的家目录下,并尝试更新你的 shell 配置文件(如 .bash_profile、.zshrc、.profile 或 .bashrc),以便每次打开新的终端时自动加载 nvm。
为了开始使用 nvm,你可能需要关闭并重新打开你的终端,或者手动执行下面的命令来载入 nvm
export NVM_DIR="$([ -z "${XDG_CONFIG_HOME-}" ] && printf %s "${HOME}/.nvm" || printf %s "${XDG_CONFIG_HOME}/nvm")"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
验证 nvm 是否已成功安装,运行
nvm --version
要安装最新版本的 Node.js,运行
nvm install node
要安装长期支持(LTS)版本的 Node.js,运行
nvm install --lts
要安装特定版本的 Node.js,你可以指定版本号,例如
nvm install 14.17.0
安装后,你可以使用以下命令来切换到已安装的任何版本
nvm use 14.17.0
要查看当前使用的 Node.js 版本,运行
node -v
要列出所有已安装的 Node.js 版本,运行
nvm ls
使用 nvm,你可以轻松管理多个 Node.js 版本,并根据需要为不同的项目使用不同的版本。
application/x-www-form-urlencoded、multipart/form-data、text/plain)XMLHttpRequestUpload对象没有注册任何事件监听器;XMLHttpRequestUpload对象可以使用XMLHttpRequest.upload属性访问。ReadableStream对象。满足上述条件的请求被视为“简单请求”。简单请求不会触发 CORS 预检请求(这里指的是浏览器)。
不符合上述简单请求条件的请求被视为复杂请求。复杂请求在正式通信之前,会先发送一个预检请求(preflight request),这是一个使用OPTIONS方法的HTTP请求,向服务器询问实际请求是否安全可接受。
复杂请求的特点包括
Content-Type,如application/json。预检请求的目的是为了确保服务器明确允许跨源请求。服务器必须正确响应预检请求,提供相应的Access-Control-Allow-Methods、Access-Control-Allow-Headers等 CORS 相关的响应头,表明服务器接受实际请求。只有当预检请求成功后,浏览器才会发送实际的请求。
简单请求和复杂请求的区别主要是为了安全考虑,通过这种机制,可以避免恶意网站对跨源资源进行未经授权的访问。其实我们可以发现,除了 GET、POST、HEAD 之外,其他类型的请求都涉及到修改数据库的内容,所以为了安全,需要进行预检。只要触发了预请求就是复杂请求
如果您喜欢这篇文章,不妨给它点个赞并收藏,感谢您的支持!
这是我的当前终端界面,我将进行详细介绍
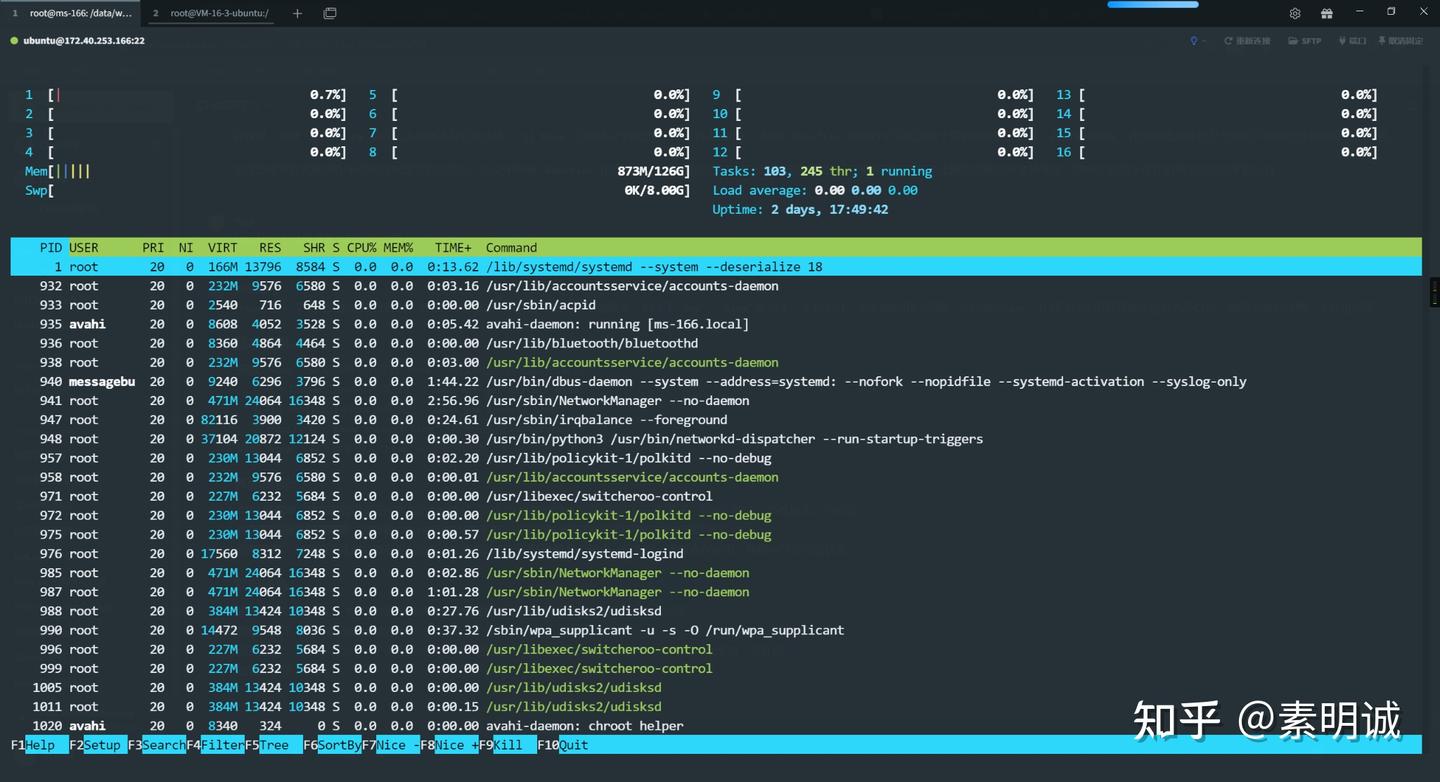 ### 顶部区域,状态
### 顶部区域,状态
CPU 使用条:每个 CPU 核心对应一个使用条,显示 CPU 的使用情况不同的颜色表示不同类型的 CPU 使用,如用户空间、内核空间等
内存 (Mem) 使用条:显示物理内存(RAM)的总使用情况颜色通常区分了用于缓存的内存和实际使用的内存,不同版本可能颜色不同
交换 (Swp) 使用条:显示交换分区(swap space)的使用情况交换空间是当物理内存不足时,用作内存的一个硬盘空间
PID:进程的唯一标识符
USER:运行该进程的用户
PRI:进程的优先级
NI:进程的 nice 值,影响其优先级
VIRT:进程使用的虚拟内存总量
RES:进程使用的、未被交换出去的物理内存大小
SHR:进程使用的共享内存大小
S:进程的状态(例如 S 代表 sleeping,R 代表 running)
CPU%:进程使用的 CPU 百分比
MEM%:进程使用的物理内存百分比
TIME+:进程自启动以来的总 CPU 时间
Command:启动进程的命令
F1 Help:显示帮助界面
F2 Setup:进入设置界面,可以配置 htop 的外观和行为
F3 Search:搜索进程
F4 Filter:过滤进程列表
F5 Tree:以树状结构显示进程
F6 SortBy:选择排序方式
F7 Nice -:降低进程的 nice 值(优先级)
F8 Nice +:提高进程的 nice 值
F9 Kill:杀死进程
F10 Quit:退出 htop
Tasks:系统中的总任务数,也就是进程数
Load average:系统在过去 1 分钟、5 分钟和 15 分钟的平均负载
Uptime:系统运行时间
如果您喜欢这篇文章,不妨给它点个赞并收藏,这对我来说意义非凡!感谢您的支持!
特点 x86 架构以其兼容性和强大的软件支持而闻名,支持从简单的数学运算到复杂的图形处理等广泛任务。
常见 CPU 型号
示例操作 在 x86 架构中,执行一个加法操作可以通过汇编指令 add eax, 2 实现,将寄存器 eax 的值增加 2。
特点 ARM 架构专注于高效能与低能耗,适合移动设备和嵌入式系统,如智能手机和平板电脑。
常见 CPU 型号
示例操作 ARM 指令集中,加法操作可以用 ADD R0, R0, #2 来实现,意味着将寄存器 R0 的值加 2。
特点 RISC-V 是一个开源指令集架构,支持高度的自定义和扩展,适合学术研究、物联网(IoT)设备和定制硬件。
示例应用 SiFive 提供的 RISC-V 处理器,如 SiFive U74,正在 IoT 和嵌入式市场中获得应用。
示例操作 在 RISC-V 中,addi a1, a1, 2 指令将寄存器 a1 的值增加 2,展示了其指令集的简洁性。
Windows:最初主要设计运行在 x86 架构上。随着技术发展,微软扩展了 Windows 支持的架构,包括 ARM 架构(如 Windows RT 和 Windows 10 on ARM),以适应更广泛的硬件平台和提高能效。
Linux:由于其开源性质,Linux 内核被移植到了几乎所有已知的硬件架构上,包括 x86、ARM、Power、MIPS 和 RISC-V 等。这种广泛的兼容性使得 Linux 成为了最灵活的操作系统之一,应用范围从嵌入式设备到超级计算机。
macOS:Apple 的 macOS 最初仅支持 Apple 自家的硬件(基于 x86 架构的 Intel 处理器)。随着 Apple Silicon(基于 ARM 架构的 M1 芯片等)的推出,macOS 也开始支持 ARM 架构,标志着苹果向更高效能硬件的转变。
Android:基于 Linux 内核,Android 主要支持 ARM 架构,考虑到绝大多数智能手机和平板电脑都采用了基于 ARM 的处理器。此外,Android 也支持 x86 架构,尤其是用于某些平板电脑和少数智能手机。
解决问题的关键在于找到关键问题
from flask import Flask, Response, stream_with_context
import time
import json
app = Flask(__name__)
def generate_sse_events():
event_id = 1
while True:
# 模拟数据生成
data = {"time": time.time(), "msg": f"Event {event_id}"}
sse_data = f"id: {event_id}\n" \
f"event: message\n" \
f"data: {json.dumps(data)}\n\n"
yield sse_data
event_id += 1
time.sleep(1) # 引入延时以模拟数据处理时间和避免粘包
@app.route('/events')
def sse_request():
return Response(stream_with_context(generate_sse_events()),
content_type='text/event-stream')
if __name__ == '__main__':
app.run(debug=True, threaded=True)
这是我在业务中封装的代码,有需要可以试一下
import { currentEnvironment } from "@/api/axios";
function buildApiUrl(): string {
return `${ currentEnvironment() === '/vnet' ? '/vnet/' : '' }api/chat-process`;
}
async function processStreamedData(reader: ReadableStreamDefaultReader<Uint8Array>, onDataReceived: (data: any) => void) {
let accumulatedText = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
accumulatedText += value;
while (true) {
const newlineIndex = accumulatedText.indexOf('\n\n');
if (newlineIndex === -1) break;
let dataBlock = accumulatedText.substring(0, newlineIndex).trim();
accumulatedText = accumulatedText.substring(newlineIndex + 2);
if (dataBlock.startsWith('data: ')) {
dataBlock = dataBlock.substring(6);
try {
const json = JSON.parse(dataBlock);
onDataReceived(json);
} catch (error) {
console.error('分析JSON时出错:', error, '来自区块:', dataBlock);
}
}
}
}
}
export async function getGeneratedData(data: any, onDataReceived: (data: any) => void) {
const response = await fetch(buildApiUrl(), {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(data),
});
if (!response.body) {
throw new Error("响应体中没有可读流数据。");
}
const reader: any = response.body.pipeThrough(new TextDecoderStream()).getReader();
await processStreamedData(reader, onDataReceived);
}
在开发时,我们常常需要处理大量的数据,这些数据可能是文件,也可能是网络请求的响应。在这种情况下,使用流(stream)可以有效地处理这些数据,避免一次性加载所有数据,从而减少内存的使用并提高应用的性能。
在这篇文章中,我将介绍如何使用 Fetch API 和 ReadableStream API 来处理流式响应数据。我将会提供具体的代码示例来展示这些概念。
Fetch API 是浏览器提供的一个现代的、强大的 HTTP 请求工具。与旧的 XMLHttpRequest API 相比,Fetch API 提供了更简洁的 API 和更强大的功能,包括流式响应。
当你使用 Fetch API 发出请求时,返回的 Response 对象包含一个 body 属性,这个属性是一个 ReadableStream。ReadableStream 表示一个可读的数据流,你可以使用它的 getReader() 方法来获取一个 reader,然后使用这个 reader 的 read() 方法来读取数据。
// 发出请求
fetch('https://example.com/data')
.then(response => {
// 获取 reader
const reader = response.body.getReader();
// 读取数据
return reader.read().then(function process({ done, value }) {
if (done) {
console.log('Stream finished');
return;
}
console.log('Received data chunk', value);
// 读取下一段数据
return reader.read().then(process);
});
})
.catch(console.error);
在这个示例中,reader.read() 返回一个 Promise,这个 Promise 的 resolve 值是一个对象,包含两个属性:value 和 done。value 是读取到的数据块,done 是一个布尔值,如果为 true 则表示数据已经读取完毕。
这样,你就可以逐块地处理数据,而不需要一次性加载所有数据。个人觉得有点像迭代器。
上述示例展示了如何逐块地读取数据,但这些数据是二进制的,如果你想处理文本数据,需要对其进行解码。
以下是一个示例
// 创建一个新的 TextDecoder 实例
const decoder = new TextDecoder('utf-8');
// 发出请求
fetch('https://example.com/text')
.then(response => {
const reader = response.body.getReader();
return reader.read().then(function process({ done, value }) {
if (done) {
console.log('Stream finished');
return;
}
// 解码数据
const text = decoder.decode(value);
console.log('Received text chunk', text);
return reader.read().then(process);
});
})
.catch(console.error);
在这个示例中,我使用 TextDecoder 对象来解码数据。TextDecoder 是一个可以将二进制数据解码为字符串的工具,它的 decode() 方法可以接受一个 ArrayBuffer 或者 TypedArray 并返回一个字符串。
有时,你可能需要处理的是 JSON 格式的数据。在这种情况下,你需要首先将所有数据读取完成,然后将其解码为字符串,最后解析为 JavaScript 对象。
fetch('https://example.com/data.json')
.then(response => {
const reader = response.body.getReader();
const chunks = [];
return reader.read().then(function process({ done, value }) {
if (done) {
// 将所有数据块连接起来,解码为字符串,然后解析为 JavaScript 对象
const text = decoder.decode(new Uint8Array(chunks.flat()));
const data = JSON.parse(text);
console.log('Received JSON data', data);
return;
}
// 存储数据块
chunks.push(value);
return reader.read().then(process);
});
})
.catch(console.error);
在这个示例中,我使用一个数组来存储所有数据块,然后在数据读取完成后,将所有数据块连接起来,解码为字符串,最后解析为 JavaScript 对象。
Solidity 是一种高级编程语言,专门用于编写运行在 Ethereum Virtual Machine(EVM)上的智能合约。它是智能合约开发的核心,类似于 Web 开发中的 JavaScript 或服务器端编程中的 Python。
Solidity 代码需要被编译成 EVM 字节码,以便在以太坊网络上运行。这一工作由 Solidity 编译器(solc)完成。solc可以通过 Node.js 的包管理器 npm 安装(作为solc-js),这允许你在本地环境中编译 Solidity 代码。
在智能合约的开发过程中,除了编写和编译代码外,还需要进行测试和部署。这些工作可以手动完成,但使用专门的开发框架会更高效、更方便。
Truffle 是一个全面的以太坊开发框架,提供了智能合约的编译、部署、测试等功能。它内置了 Solidity 编译器,因此安装 Truffle 后,你不需要单独安装solc。Truffle 还提供了一个开发环境,帮助开发者更容易地构建、管理和测试他们的 DApp 和智能合约。
Remix 是一个在线的 Solidity IDE,它允许开发者直接在网页中编写、编译、测试和部署智能合约。Remix 非常适合初学者和进行快速原型开发,因为它不需要任何本地安装。它提供了图形界面和内置的 EVM,可以非常直观地执行合约和调试。
Hardhat 是一个专注于以太坊软件开发的环境,它提供了强大的功能,如 Solidity 的编译、智能合约的部署、测试脚本编写和执行,以及网络管理。Hardhat 的特色是它的 Hardhat Network,一个用于开发的本地 Ethereum 网络,支持高级调试功能。
Solidity 是基础,无论使用哪个开发环境或框架,最终都是在编写 Solidity 代码。
solc 是将 Solidity 代码转化为可以在以太坊上执行的字节码的工具。它可以单独使用,也可以作为其他工具的一部分(如 Truffle 和 Hardhat 内置了 solc)。
Remix 适合学习、快速原型开发和小项目。
Truffle 提供了一个成熟的开发环境,适合大型项目和团队合作。
Hardhat 提供了先进的开发工具和灵活性,适合追求最新技术和自定义开发流程的开发者。
预训练是机器学习模型开发过程的第一阶段,通常在大规模的数据集上进行。这个数据集包含了广泛的语言特征和世界知识,目的是使模型能够学习到尽可能多的信息。预训练模型如 BERT、GPT 等,通过这种方式获得了处理各种下游 NLP 任务(如文本分类、情感分析、问题回答等)的能力。这个过程需要大量的数据、计算资源和时间,因此成本相对较高。预训练的目的是训练出一个具有泛化能力的模型,它不针对任何特定任务进行优化。
微调是在预训练模型的基础上进行的,目的是调整模型以适应某个特定任务或领域。这通过在特定领域的较小数据集上进一步训练模型来实现,调整模型参数以优化特定任务的性能。相比于预训练,微调需要的数据量更少,计算资源和时间成本也相对较低。微调使得预训练模型能够在特定任务上获得更高的精度和效率。
**数据需求:**预训练需要大规模、多样化的数据集,以学习广泛的语言特征和世界知识。微调则侧重于特定任务或领域的数据,数据量相对较小。
**计算资源:**预训练大型模型通常需要高性能的计算资源,如 GPU 或 TPU 集群,且训练时间可能持续几周甚至几个月。微调阶段由于数据量更小,计算需求也相对较低,可以在较短的时间内完成。
**时间成本:**与计算资源相对应,预训练的时间成本显著高于微调。微调可以在几小时到几天内完成,而预训练可能需要几周到几个月。
因此,微调则更加灵活、高效,允许研究人员和开发者快速适应和优化特定任务,成本相对较低。
npm install nosleep.js
https://github.com/richtr/NoSleep.js/### 在展示的组件内加上以下内容
import NoSleep from 'nosleep.js';
// 创建 NoSleep 实例
var noSleep = new NoSleep();
// 在用户交互的事件回调中激活
function enableNoSleep() {
noSleep.enable();
// 取消事件监听以避免重复激活
document.removeEventListener('click', enableNoSleep, false);
}
// 添加事件监听,等待用户交互
document.addEventListener('click', enableNoSleep, false);
 ### 选择系统
### 选择系统 ### 选择 BitLocker
### 选择 BitLocker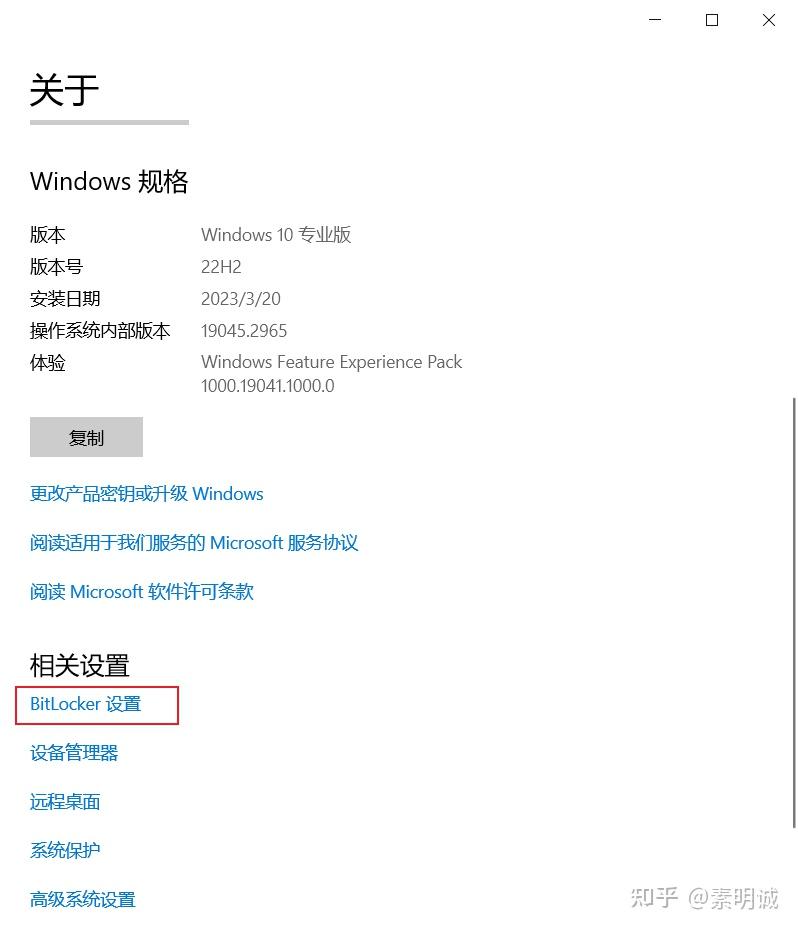 ### 选择关闭
### 选择关闭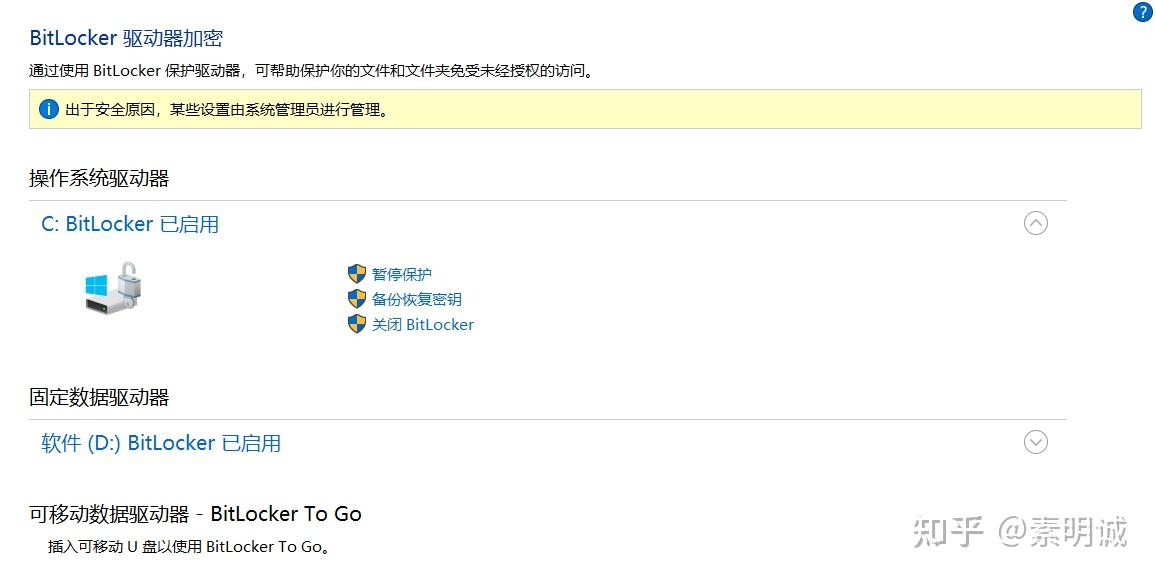 ### 解密
### 解密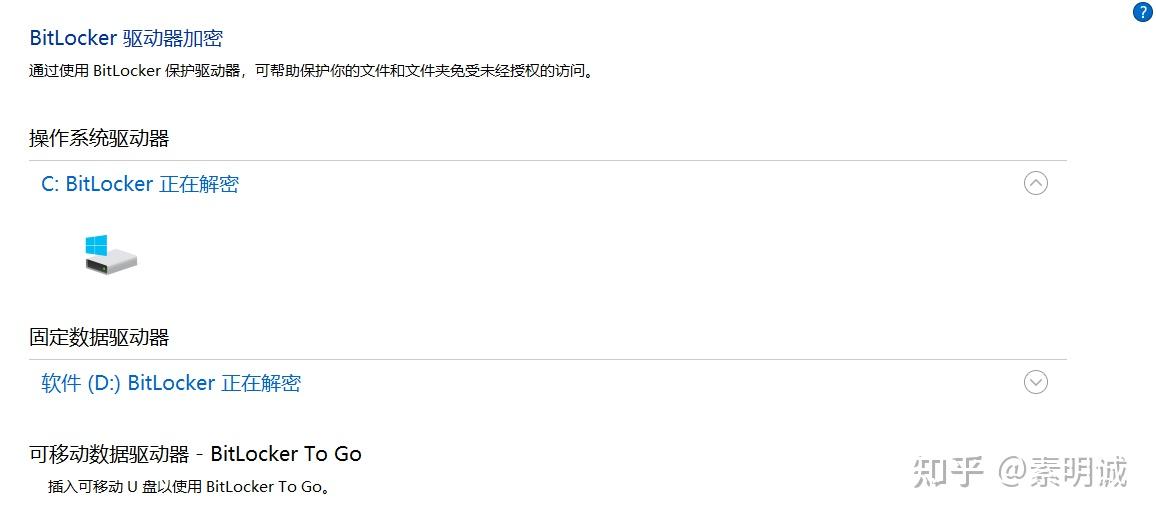 ### 等待解密完成
### 等待解密完成